
From Artifact to Production: Integrating and Refining Lattice Cryptography Acceleration
This post follows on from the recent cross-post from our research collaborators at MPI-SP about their innovative design for ML-KEM and ML-DSA acceleration. Today, we’ll focus on what happened in between the researchers creating the initial implementation and now, when we have lattice cryptography support derived from their work in our production open-source silicon repository.
This post follows on from the recent cross-post from our research collaborators at MPI-SP about their innovative design for ML-KEM and ML-DSA acceleration. Today, we’ll focus on what happened in between the researchers creating the initial implementation and now, when we have lattice cryptography support derived from their work in our production open-source silicon repository. For more on this collaboration with a higher-level and broader lens, look out for our upcoming joint talk at Real World Crypto in March!
We believe strongly that open-source projects and academic research reinforce one another. Open-source projects give researchers a realistic starting point for experiments so they don’t need to build everything themselves or reverse-engineer a blackbox product in order to publish papers. And in return, open-source projects can benefit from cutting-edge research being developed natively on their codebases.
Although research and open-source development can happen completely independently, we have found that early and frequent communication helps both sides. Researchers can offload non-novel, engineering-focused tasks to open-source developers and ask questions about the codebase. Developers can get advance insight about research directions and can share their project’s constraints and priorities to increase the odds of adoption. Finally, and perhaps most importantly for both sides, open-source developers can integrate and refine research artifacts and then include them into projects for real-world impact. In the case of the ML-KEM and ML-DSA collaboration, which introduced a significant amount of new code and features to an existing open-source codebase, this was a complex task that ranged from improving RTL design verification coverage to optimizing the memory and performance usage of the code.
The following graph1 shows how the overall area and latency for the design improved over time as both ZeroRISC engineers and academic researchers worked on it:

Everything in the graph is normalized to the latest version, so it’s easier to see lots of very different metrics with different units in one chart. The “baseline” measurement is from the Towards ML-KEM and ML-DSA on OpenTitan2 paper, which evaluated an implementation of ML-KEM and ML-DSA on the base OTBN design, just with more area added to support the datatypes. You can see that initially, the latency for ML-KEM and ML-DSA was 8-10x higher than it is now! The Towards paper so dramatically improved the latency that it’s hard to read the graph with the baseline there. Here’s the same data but without the baseline measurement so the differences between other versions are clearer:
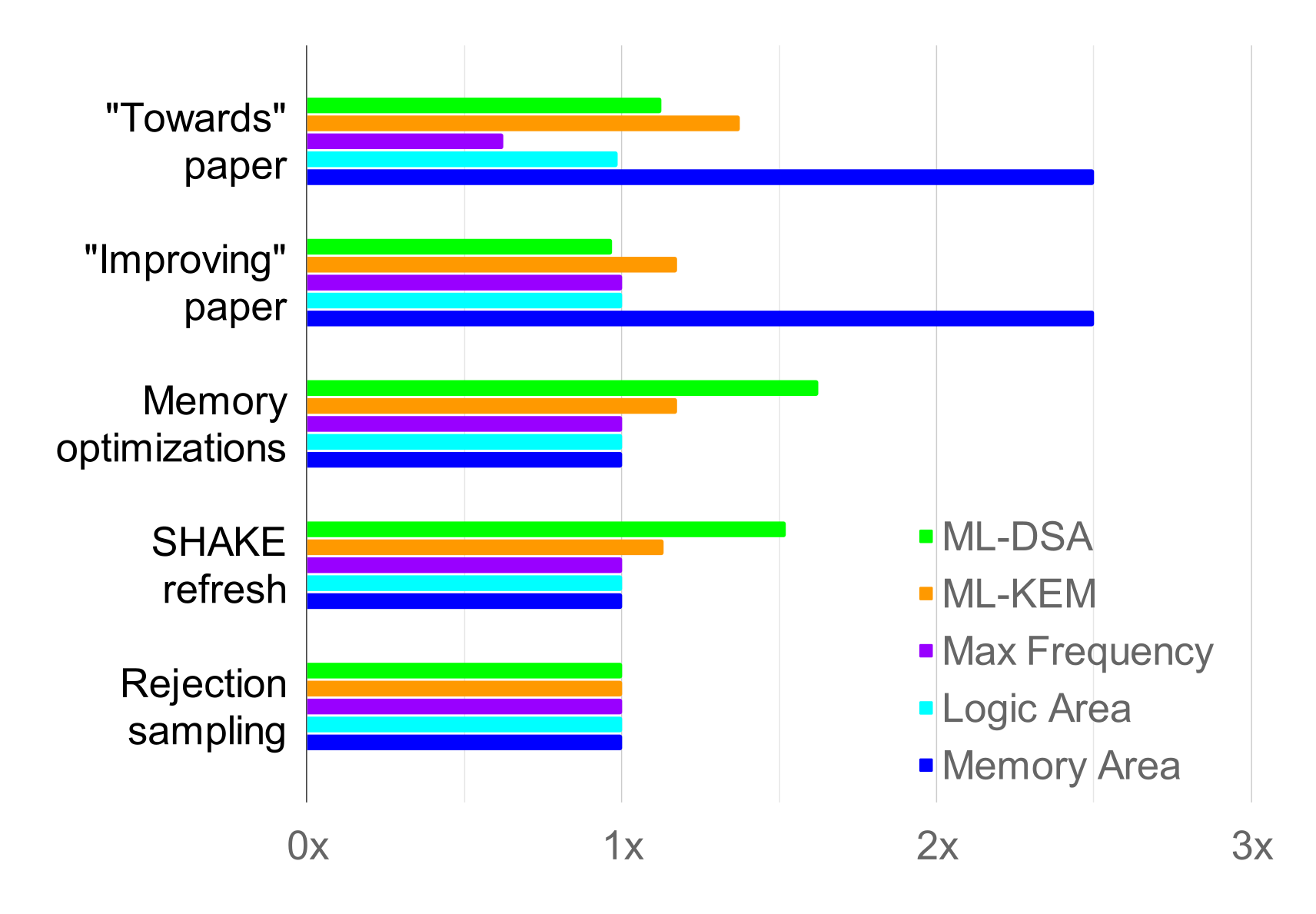
Following up from Towards, the subsequent Improving ML-KEM and ML-DSA on OpenTitan3 paper further improved latency for both ML-KEM and ML-DSA, and brought the maximum frequency up. After (or in fact, concurrent with) these vital contributions from academia, ZeroRISC engineers stepped in to refine the results. First we applied stack optimizations, which brought the memory area down at the cost of latency for ML-DSA. However, we were then able to mostly recover the latency costs and accelerate ML-KEM with improvements to the SHAKE hardware interface and both schemes’ rejection sampling routines.
In the rest of this post, we’ll go through each step of the optimization process and also discuss how we worked together with academic partners.
Collaboration setup
Before we could start any of the optimizations, it was clear that it would be helpful for both us and our academic collaborators to work on the same repository so we all had shared state. Since we would be doing our optimizations in parallel with new research, it was important to stay in sync and make sure the changes didn’t diverge too much.
We initially limited access to this repository to protect collaborators’ ability to publish and minimize the chance that partial results could be taken out of context. However, we also wanted future readers to have a faithful record of how the project evolved. Especially in security, keeping context like discussions of technical tradeoffs and the ordering of changes in the public record is a core advantage of open-source development. We therefore worked from a private repository initially, then changed the visibility to public after the new research was complete.
The results from the Towards ML-KEM and ML-DSA on OpenTitan paper had already been released as an artifact in a dedicated git repository. This code was based on a relatively old version of the OpenTitan codebase, so the first challenge was to make the changes work with a more recent version. Unfortunately, the artifact had erased the git history, so we needed to copy the code over and do manual surgery on it to make it run rather than rebasing.
Once the code was running, we set up some very basic checks to protect the main branch from breaking changes. With the basic infrastructure in place, we were ready to start optimizing the hardware and software.
ML-DSA stack optimization
The first thing we needed to do was improve the memory usage of ML-DSA. The initial implementation would have required the ACC coprocessor to have 128KiB of data memory, up from…4KiB in the original OTBN design. This would cost too much area for such a small embedded device, but luckily we were not the first to address this problem; there was substantial existing research in papers like Dilithium for Memory Constrained Devices4 and Compact Dilithium Implementations on Cortex-M3 and Cortex-M45, as well as open-source implementations like pqm4. Another resource consulted during this memory optimization process was Warp Drive Engineering6, Amber Sprenkels’s PhD thesis, which overlaps with the other two papers.
Following these references, we experimented with different memory optimizations. This table summarizes their effect on the stack needed for ML-DSA-87 signing, the most memory-hungry operation:
| optimization | new stack size (bytes) | change (bytes) | approx. slowdown |
| Stream matrix A | 56672 | -64160 | 125% |
| Stream y | 49504 | -716 | 3% |
| Stream s1, s2, t0 | 19808 | -29696 | 14% |
| Compress w1 | 11872 | -7936 | 2% |
| Accumulate y | 10848 | -1024 | 0.1% |
As you can see from the table, most of the performance gains come from streaming various values. The ML-DSA signing procedure is basically a big rejection loop that keeps looping until it generates a valid signature, so naturally most performance-sensitive implementations compute as much as they can before the loop and then keep it live until the operation is complete.
However, these values can be huge. The matrix A, for example, is a k × l matrix where each entry is a polynomial of 256 24-bit coefficients each. Vectorized implementations like ours will probably store each coefficient in a 32-bit slot, for a round 1024 bytes = 1KiB per polynomial. Depending on the parameter set, the matrix has 16-56 entries, so that means a whopping 56KiB for ML-DSA-87, just for A!
In a memory-optimized implementation, we trade off performance for space by recomputing A again from its seed on every iteration of the sign loop. We never need to keep the entire matrix in memory; we stream it as we perform a matrix-vector multiplication and store only the resulting vector. The matrix expansion runs on SHAKE operations, and helpfully we have a hardware SHAKE to help minimize the cost of recomputation. A 125% slowdown sounds rough until you see that Compact Dilithium Implementations reported 234-289% slowdowns for the same optimization on Cortex-M4!
While it’s possible to reduce ML-DSA-87 all the way down to 8kB of stack based on the papers we referenced, further memory optimizations would also come at a performance cost and 11kB is low enough for our initial requirements. Accounting for I/O buffers, constants, and expected overhead from masking, we think that this amount of stack reduction will be sufficient for our goal of fitting first-order-masked ML-DSA-87 in 32KiB. We may need a few additional smaller adjustments, for example to how we store compile-time constants, but we’ll reserve those for when we have more precision on exactly how much space we need to make.
In the benchmarks we ran for the chart at the top of this post, we see overall slowdowns for memory optimizations of 82%, 84%, and 138% for ML-DSA-44, -65, and -87 signing respectively7. This is surprisingly good; in our blog post a little over a year ago we expected 200-400% slowdowns. Part of that difference is because we didn’t have to implement the most extreme optimizations, and part of it is because of architectural differences between ACC and Cortex-M4.
We later applied a subset of the same memory optimizations to key generation and verification operations. It’s easier to optimize these than signing; while the signing procedure is a loop that needs most values to remain live until the end of the computation, key generation and verification generally process each value only once. For the same reason, the performance cost of memory optimizations were much smaller on key generation and verification: about 0.1-0.4%.
Hardware and design verification integration
We concluded from our memory optimization experiments that 32KiB each of data and instruction memory for the coprocessor will be sufficient for first-order-masked ML-DSA-87. That still required a hardware change to update from 8KiB of instruction and 4KiB of data memory in the original design. To support ML-KEM and ML-DSA acceleration on ACC, a vector ISA extension, new adder, new multiplier, and miscellaneous control/datapath registers like unique WSR/CSR registers were also added.
It became evident that this configurability of ACC should be expanded to the RTL itself. To accommodate for the differing design constraints the ML-KEM and ML-DSA capabilities were controlled behind the AccPQCEn SystemVerilog parameter. The instantiation of the vectorized adder, multiplier, and PQC unique datapaths are contingent on the usage of the AccPQCEn parameter. As a result, we can eliminate the additional hardware overhead required for ML-KEM and ML-DSA on ACC when the PQC algorithms are not desired.
Using SystemVerilog parameters has a considerable impact on the design verification (DV) and coverage efforts. The original ACC simulation config was turned into a base configuration to specify the DUT being tested, alongside testcases and common simulation environment variables. A pair of configurations were created to inherit the base, while each extended their appropriate AccPQCEn parameter value and DV dependencies. The testing infrastructure relies on the generation of randomized instructions, often organized into a subset of groups referred to as a snippet. These snippets cover the entire range of instructions, from straight-line instructions like arithmetic, to conditional instructions like branches or jumps. The more complex snippet generators include illegal instructions aimed at verifying ACC behavior, including bad loops, or an illegal CSR/WSR address. The result of snippet generation is an assembly test program to run on both ACC and accsim, a specialized simulator of ACC’s expected behavior, for comparison.
In order to collect coverage metrics for ACC, we needed to expand the existing snippet infrastructure. Firstly, we expanded the straight-line instruction snippet to include the new vector ISA instructions. For coverage, we expanded the set of covergroups in order to capture the new set of instructions and instruction encodings. The introduction of new CSR/WSR registers also constituted an expansion of the related covergroup, with appropriate bins and crosses based on the parameter value. At the same time, we updated the bignum_insn.yml for ACC to include a flag on all instructions only supported by the AccPQCEn parameter. This allowed us to dynamically adjust the list of valid and illegal instructions generated for each test case. As previously mentioned, accsim is an ISS model of ACC and runs in lockstep to compare instruction execution, processor state, and register values. The IP and DV environment parameterization was also extended to the simulation model.
In addition to the new instruction datapaths, we introduced a side-load interface connection between KMAC and ACC. Within the DV environment, a UVM agent was created for the KMAC interface to respond to hash requests generated by ACC, and drive the appropriate digest response. Generating KMAC requests in ACC requires a sequence of instructions to be executed in order to write to the appropriate WSR/CSR registers. This behavior constituted a more complex snippet generator, in order to evaluate coverage metrics like line, toggle, and conditional etc. The generator works by creating a sequence of instructions to configure the hashing mode into SHA3/SHAKE with different drive strengths and creating a variable length message. The end of the snippet attempts to read the digest from KMAC, and for XOF’s a variable number of reads in order to exhaust the Keccak state. Included in this testing is the ability to generate oversized and undersized message payloads to KMAC in order to test ACC’s response.
Improved multiplier and adder
As we were making the above changes, Ruben Niederhagen at Academia Sinica and Hoang Nguyen Hien Pham at MPI-SP made further progress on the accelerated ISA design. In their paper Improving ML-KEM and ML-DSA on OpenTitan, they adjust the original ISA to remove the vectorized modular multiply instruction and replace it with an updated non-modular vector multiply that has additional modes to make software modular reduction faster. This resulted in better throughput overall for the multipliers, reducing cycle counts for top-level ML-KEM and ML-DSA operations up to 17%. Further adjustments they made to the vector adder improved the design’s maximum frequency dramatically, by 36-75% depending on the ASIC or FPGA toolchain. Despite all of these latency improvements, area is hardly affected, with their paper’s two ASIC targets showing either a 3% decrease or a 6% increase in area.
Of course, given the impressive results, we wanted to integrate these new changes. As a result of frequent communication and a shared development repository, we knew to expect the update and the process was straightforward.
We also put the researchers in contact with Andrew “bunnie” Huang and Robert Schilling, who were able to run the designs through additional synthesis pipelines. This allowed the researchers to better understand how the design performed with different synthesis tools, as well as giving us at ZeroRISC early feedback on how the design might work for our customers and what integration work we might need to plan for.
KMAC interface improvements
As we integrated the results from the Towards and Improving papers, we made some tweaks to the KMAC/ACC interface as well. In the original implementation from Towards, software sets the length of a SHAKE/SHA3 input at the start of the computation and then repeatedly writes to the kmac_msg register. The KMAC block reads all bytes from each write until the expected length is reached. However, sometimes ML-KEM and ML-DSA hash multiple concatenated values of different lengths, and it’s not convenient (especially when memory is tight) to copy everything into a single buffer. For this reason, we added a 32-bit CSR register kmac_partial_write. Writing to the register applies a byte mask to the next word written to the kmac_msg_data WSR register. After applying the partial write value the kmac_partial_write CSR clears itself until written to again. This makes it easier to send multiple values to KMAC without copying, improving performance and providing greater flexibility.
We also reduced the frequency of ACC stall cycles attributed to the KMAC interface. Attempting to read a digest with the bn.wsrr instruction that is not yet ready will intentionally incur a stall until KMAC is finished. The masked Keccak implementation in KMAC requires 4 cycles per round, with additional clock cycles for the ingress and egress of data. For the Keccak XOF’s used by ACC, there is an egress overhead of 3 clock cycles to shift out the new digest so long as the Keccak state is not exhausted. ACC uses two new interface ports, next and hold, to assert control over KMAC during XOF computations. The hold signal is used to maintain exclusive control of KMAC for extended periods as next is asserted by ACC whenever a new 256-bit digest is requested. Originally, the next signal’s assertion was bound to the bn.wsrr instruction execution when starting a digest read. This was guaranteed to incur a stall for the length of the data shift period on every read.
To combat this stall we implemented an eager refresh of the digest. We recognized that in an ideal scenario we perform intermediate operations on ACC while a new digest is being loaded. To accomplish this, the next signal assertion was coupled to the previous digest read. In doing so we are able to speculatively request the next digest from KMAC, reducing the maximum stall cycles per read by 1. This change already had a noticeable impact on latency for ML-DSA and ML-KEM (about 5% and 4% overall, respectively). The larger performance improvement comes from the fact that a new digest read request from bn.wsrr is not strictly necessary to load a value to ACC. This opened the option to improve software optimizations by executing intermediate operations between digest loads, and remove the guaranteed KMAC stalls.
Rejection sampling speedups for ML-DSA
One of the most time-consuming steps in all ML-DSA operations is the sampling of the matrix A. Each polynomial in the matrix must be separately expanded from a seed value using the SHAKE XOF. The expansion consists of sampling 3 bytes at a time from the SHAKE output, clearing the high bits and rejecting all inputs that are still greater than the 23-bit modulus q = 8380417 until we sample 256 valid coefficients. Even with hardware acceleration for the actual SHAKE computations, this operation took 40-60% of cycles for all top-level ML-DSA operations!
The first opportunity we found to speed up the rejection loop was to vectorize the sampling routine. Since q is actually quite close to 223, rejections during ML-DSA sampling are rare. A random 23-bit number has a 99.9% chance of being within the valid range. So we wondered – since coefficients were discarded so rarely, could we push complexity out of the hot loop and into specialized discard logic that would run only rarely? The answer was a resounding yes.
Thanks to the fast vectorized ISA we have from the Towards paper, we can sample, unpack, and store candidate coefficients several at a time. Only once we assembled 256 coefficients speculatively into a polynomial did we actually check the bounds. Again taking advantage of the fact that rejection is rare, the bounds-check is vectorized; we subtract the modulus from 8 coefficients at a time and mask out the bits that will be set if the subtraction underflowed (i.e. the modulus is greater than the coefficient). Then, we can check the zero flag to see if all 8 coefficients are in bounds, which is true 99.2% of the time on average.
In the rare case that there is an invalid coefficient in the vector, we run a specialized discard routine to locate the bad coefficient, shift the whole polynomial one place, and then sample a new coefficient at the end. This discard routine is comparatively slow, but it’s so rare that it doesn’t matter; the speedup we observed from this initial vectorization was 20-40% across each top-level ML-DSA operation.
We were then able to gain further speedups by taking advantage of the KMAC hardware tweaks. Since it’s predictable when the SHAKE digest will need to wait ~100 cycles to refresh, we could unroll the loop and use time when we’d otherwise stall to precompute the check for bad coefficients, keeping track of the index of the first out-of-bounds coefficient. Most of the time (~78% of polynomials), there will be no bad coefficients at all and we can skip the check-and-discard logic entirely. Otherwise, we can immediately know where to start the discard process. We could also send the input to KMAC a bit early to avoid stalls before the first digest was ready. These further improvements brought us to an overall 52% speedup for top-level ML-DSA operations.
Rejection sampling speedups for ML-KEM
Like ML-DSA, we also found that core ML-KEM operations were bottlenecked by rejection sampling. Prior to our optimizations in this section, the introduction of eager KMAC refreshing and a carefully optimized NTT routine had already eliminated the other typical bottlenecks one might typically find in an ML-KEM implementation: benchmarking ML-KEM-512 revealed that the poly_gen_matrix routine, which generates the public matrix ÂT during encryption, contributed around 35-40% of cycles to decapsulation.
Recall that in ML-KEM, the ÂT matrix is a k × k matrix, where k = 2, 3, 4 for ML-KEM-512, ML-KEM-768, and ML-KEM-1024 respectively. Each entry of this matrix is deterministically sampled from a public key by passing it through SHAKE-128 just like with ML-DSA.
Digging into poly_gen_matrix’s performance, we found that processor stalls were a significant contributor to latency, representing 25% of the overall cycles spent in poly_gen_matrix. These stalls weren’t a result of waiting on the KMAC engine (there were sufficient delays between KMAC calls that only the initial SHAKE squeeze resulted in a stall) but instead arose from branching in the core sampling logic. Indeed, as part of defense against Spectre-style attacks, the ACC is designed to always require two cycles per branch regardless of whether a branch is taken or not. While this is necessary for security, it also means that during branching-heavy code such as a rejection sampling loop, the ACC can spend a significant amount of time in processor stalls.
We might be tempted to try to employ the same eager sampling trick that worked for ML-DSA. One crucial detail with ML-KEM, however, is that the rejection sampling routine rejects coefficients at a much higher rate than ML-DSA does. ML-KEM coefficients are sampled modulo q = 3329 by sampling 12-bit integers, meaning that a candidate coefficient will only be accepted with probability 3329/212 ≈ 0.813..., or about 81.3% of the time. As such, the technique used to optimize ML-DSA’s poly_uniform won’t work, as too many incorrect samples would accrue to handle efficiently post-hoc.
Since we couldn’t amortize rejection handling costs as in ML-DSA, we had to find a way to eliminate stalls while encountering new candidate coefficients. Originally, the core of the rejection sampling logic in _poly_uniform_inner_loop would review 20 coefficient candidates in the wide register shake_reg containing the latest SHAKE-128 output. Accepted coefficients needed to be stored in memory at 16-bit boundaries to leverage vectorized instructions later, so an accumulator wide register was used to hold 256 total bits/(16 bits/coefficient) = 16 coefficients and an accumulator_count register was used to track when the accumulator register was full and needed to be written out.
(coefficients in accumulator rejection sampled from shake_reg)
┌────┬────┬────┬────┬────┬────┬────┬────┬── ──┬────┬────┐
│0aaa│0bbb│0ccc│0ddd│0eee│0fff│xxxx│xxxx│x ... x│xxxx│xxxx│ accumulator
└────┴────┴────┴────┴────┴────┴────┴────┴── ──┴────┴────┘ (wide register)
0 1 2 3 4 5 6 7 8 14 15
▲
│ └─ accumulator_count = 6
(written out (general purpose register)
│ to memory
once full)
▼
|----|----|----|----|----|----|----|----|- ... -|----|----|- ... coefficient buffer
▲ (ACC memory)
└─ write-out memory pointer
(general purpose register)The full process for the core rejection sampling loop initially looked like the following (see here for the implementation):
- For 20 times:
- (Branch #1) If our write-out memory pointer is past the last valid address, jump to (*) to skip further sampling
- Fetch a 12-bit candidate coefficient
candby masking the least significant bits of the SHAKE-128 output - Compare
candto q = 3329 - (Branch #2) If the carry bit isn’t set (i.e. 3329 <=
cand< 4096), jump to (*) to reject the candidate - Shift
candintoaccumulatoraligned to a 16-bit boundary - Add 1 to
accumulator_count - (Branch #3) If
accumulator_count< 16, jump to (*) to skip writing out to memory - Write
accumulatorout to memory and increment the write-out memory pointer - Reset
accumulator_countto 0 to indicate that theaccumulatoris empty - (*) Shift the SHAKE-128 output right to discard the 12 least significant bits
- Return to rest of
poly_gen_matrix
The lines labeled “Branch #1,” “Branch #2,” and “Branch #3” were where the majority of branch stalls arose from, so these were the lines that were targeted. Our first observation was that Branch #1–the branch signaling that poly_gen_matrix had already sampled its last coefficient–was only ever taken once in dozens of calls to this hot loop. Because of the necessarily unpredictable nature of rejection sampling, we couldn’t eliminate this check entirely, but we found that in some cases it could be elided.
Indeed, to reduce the impact of Branch #1 in the above logic, we found that we could separate out the above loop into two cases: one where at least 20 coefficients were still needed and Branch #1 could be eliminated, and another where we need Branch #1 since fewer than 20 coefficients are needed (new logic in bold, skipped checks struck through):
- Subtract the first address past the output coefficient buffer from the write-out pointer
- Compare it to 64 bytes (= 2 accumulator write-outs, greater than 20 coefficients)
- If the carry bit is set, jump to (**) to skip unnecessary checks
- For 20 times:
- (Branch #1) If our write-out memory pointer is past the last valid address, jump to (*) to skip further sampling
- Fetch a 12-bit candidate coefficient
candby masking the least significant bits of the SHAKE-128 output - Compare
candto q = 3329 - …
- Return to rest of
poly_gen_matrix - (**) For 20 times:
(Branch #1) If our write-out memory pointer is past the last valid address, jump to (*) to skip further sampling- Fetch a 12-bit candidate coefficient
candby masking the least significant bits of the SHAKE-128 output - Compare
candto q = 3329 - …
- Return to rest of
poly_gen_matrix
Since skipping this check eliminates two cycles per iteration in a hot loop, it more than compensates for the small extra bit of logic to check whether 20+ coefficients are still needed.
This also led to a nice follow-on optimization, as now executing the latter loop implies that there are 20+ coefficients to generate. Since this is more than the 16 coefficients accumulator can hold, we can eagerly sample as many coefficients as there are open slots in accumulator without worrying about filling it. This means we can eliminate Branch #3 from this new eager step, only handling potential accumulator fills afterward.
- Subtract the first address past the output coefficient buffer from the write-out pointer
- Compare it to 64 bytes (= 2 accumulator write-outs, greater than 20 coefficients)
- If the carry bit is set, jump to (**) to skip unnecessary checks
- For 20 times:
- (Branch #1) If our write-out memory pointer is past the last valid address, jump to (*) to skip further sampling
- Fetch a 12-bit candidate coefficient
candby masking the least significant bits of the SHAKE-128 output - Compare
candto q = 3329 - …
- Return to rest of
poly_gen_matrix - (**) Subtract
accumulator_countfrom 20 to get the remaining number of slotsaccumulatorhas open: - For that number of times:
(Branch #1) If our write-out memory pointer is past the last valid address, jump to (*) to skip further sampling- Fetch a 12-bit candidate coefficient
candby masking the least significant bits of the SHAKE-128 output - Compare
candto q = 3329 - …
(Branch #3) Ifaccumulator_count< 16, jump to (*) to skip writing out to memoryWriteaccumulatorout to memory and increment the write-out memory pointerResetaccumulator_countto 0 to indicate that theaccumulatoris empty- …
- For the remaining number of times:
(Branch #1) If our write-out memory pointer is past the last valid address, jump to (*) to skip further sampling- Fetch a 12-bit candidate coefficient
candby masking the least significant bits of the SHAKE-128 output - Compare
candto q = 3329 - …
- Return to rest of
poly_gen_matrix
At this point, the vast majority of the stalls from Branches #1 and #3 have been eliminated. Branch #2 is a bit trickier though, as it represents the actual rejection sampling branch, which is intrinsically necessary as a conditional piece of logic. For this, we actually move the conditional logic away from branching instead using the bn.sel instruction to select between two versions of accumulator depending on whether a candidate should be accepted.
In detail, recall that Branch #2 when taken skips several steps, including:
- Shifting the candidate into
accumulator - Updating the
accumulator_count - Checking if
accumulator_countindicatesaccumulatoris full 3a. If so, storing the contents ofaccumulatorto memory and resettingaccumulator_count
To handle (1), we simply replace shifting the candidate into accumulator with shifting it into a separate wide register, selecting between the contents of new register and the old one using the carry flag in a single instruction:
/* Shift the candidate into `accumulator`, storing the result in `accumulator_new` wide register. */
bn.rshi accumulator_new, cand, accumulator >> 16
/* Select between the previous `accumulator` and `accumulator_new` based on the carry flag. */
bn.sel accumulator, accumulator_new, accumulator, FG0.CFor (2), we can craftily make use of the fact that the carry flag is the least significant bit of the flags CSR, so we can mask it and add it to the accumulator_count
csrrs a4, 0x7C0, zero /* Read flags */
andi a4, a4, 1 /* Mask carry flag to detect underflow */
add accumulator_count, accumulator_count, a4 /* Move to next slot iff not rejected */(The perhaps overly astute reader will note that this add is actually a sub in the most recent code; this is because accumulator_count was swapped to count the number of remaining slots to allow a minor performance improvement.)
Item (3) is actually just the Branch #3 that we eliminated from the eager sampling loop. It needs to remain in the following loop that handles accumulator rejection, but it’s fine (and performance-wise advantageous) to run this check superfluously even if a candidate wasn’t accepted this iteration. Note that we do occasionally end up triggering a second write-out of the accumulator to memory, but that in every such case the written value is exactly what was already present, maintaining correctness of the rejection sampling loop.
With these last small tweaks to eliminate Branch #2, we have completely eliminated 30-40% of the overall processor stalls, reducing ML-KEM decapsulation cycle counts by about 20% across all parameter sets. Note that the eager sampling loop we added is now entirely branchless, despite the fact that we couldn’t apply the same trick as ML-DSA. The updated implementation of _poly_uniform_inner_loop can be found here.
The glorious rebase
After all of the changes above were merged into the development repository, we felt that the hardware and software implementation was mature enough to integrate into ZeroRISC’s primary repository. While our testing set up let us know our software tests for ACC were passing, that was about it. At the end of the day though, how much work could it really be to upstream this? As it turns out, quite a bit, and certainly emphasises the importance of a high quality testing framework.
Despite the development repository sharing a common commit history with our upstream, it hadn’t been synced for roughly six months. We had contributed nearly 200 commits between KMAC, ACC, and SW over that period, while the upstream was accumulating commits at a much more rapid pace. Thankfully, the vast majority of commits did not have conflicts, as development was reasonably independent. One wrinkle: during the development period, a commit was merged upstream that changed the endian representation of crypto tests for ACC supported algorithms, while we had been writing new crypto tests for ML-KEM and ML-DSA based on the format used at the time of the development repository’s creation. After resolving this merge conflict, which impacted a large number of the now 300 crypto tests, we were inching closer to an upstream merge.
The remaining problem? A very large wall of red lint marks. Through our development we either modified or created 237 files, a mixture of SystemVerilog, Python, Assembly, and a few other formats on which we performed extensive lint checks for. Every time we fixed one lint check, it would free up the next one to run, leading to an iterative cycle. Finally we had all green lint checkmarks, but now a failing FPGA test. The FPGA tests synthesize the entire top-level design and load software tests to execute and verify IP blocks and that our cryptographic functions are working properly with KAT test vectors. As it turns out, we had created a small bug in the development process, which our minimal research testing framework did not catch. Nevertheless, one more commit and we were finally done capstoning a multi-year, multi-party multi-publication research collaboration that resulted in an open-source, state-of-the-art Asymmetric Cryptographic Co-processor.
This merge isn’t the end of our refinement work; far from it. We have more ideas for how to improve the code size metrics and are working with our research collaborators on masking techniques and even potential additional ISA tweaks. Stay tuned for more, including the upcoming joint talk at Real World Crypto in Taipei!
Interested in learning more? Sign up for ZeroRISC’s early-access program or contact us at info@zerorisc.com.
Some quick notes on graph methodology: The latency metrics were from running 10 identical pseudorandom tests per parameter set and operation on each version at commits 1afe29860e, 3b6febaadc, aa7b8153c1 dbd3341285, and 37250106b5. We took the average of the 10 tests for each operation, then added the averages for ML-DSA and ML-KEM respectively and normalized to the latest version. The baseline numbers were back-solved by applying the speedups from the Towards ML-KEM and ML-DSA on OpenTitan paper, since that code was never in our repository. Although 10 tests is not enough for statistical significance on the absolute number of cycles, particularly for ML-DSA signing, it’s good enough for a sense of the relative difference between two versions if the tests are identical. The logic area and frequency numbers are from the ASIC Genus 7nm counts in the paper Improving ML-KEM and ML-DSA on OpenTitan. The memory area assumes 32KiB of instruction memory in all cases and rounds up to the next power of 2 for data memory (e.g. if ML-DSA signing takes 20KiB and everything else fits in 16KiB, we still round to 32KiB).↩︎
Towards ML-KEM & ML-DSA on OpenTitan. Amin Abdulrahman, Felix Oberhansl, Hoang Nguyen Hien Pham, Jade Philipoom, Peter Schwabe, Tobias Stelzer, Andreas Zankl. IEEE S&P 2025. https://eprint.iacr.org/2024/1192↩︎
Improving ML-KEM and ML-DSA on OpenTitan: Efficient Multiplication Vector Instructions for OTBN. Ruben Niederhagen, Hoang Nguyen Hien Pham. CHES 2026. https://eprint.iacr.org/2025/2028↩︎
Dilithium for Memory Constrained Devices. Joppe W. Bos, Joost Renes, Amber Sprenkels. AfricaCrypt 2022. https://eprint.iacr.org/2022/323↩︎
Compact Dilithium Implementations on Cortex-M3 and Cortex-M4. Denisa O. C. Greconici, Matthias J. Kannwischer, Amber Sprenkels. https://eprint.iacr.org/2020/1278↩︎
Warp Drive Engineering: Implementing and Optimizing the Dilithium Signature Scheme. Amber Sprenkels, PhD thesis. 2024. https://electricdusk.com/files/2024-11-03_thesis.pdf↩︎
The slowdown for ML-DSA-87 does not match the table exactly because the table slowdown approximations were calculated based on single tests, at the time the memory optimizations were developed. Since this work overlapped with improvements to the hardware multiplier and adder, we later reapplied the memory optimizations on top of that work. Because we developed benchmarking infrastructure later on top of that new state, it was easier to get comparison numbers for “improving” vs “improving with memory optimizations” than to get the comparison for the original memory optimization commits. But of course, since the new multiplier and adder changed the performance characteristics of the implementation, the slowdown from memory optimizations also shifted a bit.↩︎
Accelerating Post-Quantum Cryptography on OpenTitan-based Designs: Flexible Hardware for a Secure Future
We describe extensions based on the OpenTitan Big Number (OTBN) coprocessor to enable very efficient support for recently standardized lattice-based post-quantum crypto systems, achieving speed-ups of a factor of 6--9x compared to the baseline. The resulting extended design for an Asymmetric Cryptography Coprocessor (ACC) and software implementations targeting the same are open-sourced and slated for adoption by GlobalPlatform's Trusted Open Source Silicon Task Force. Follow-up work has improved ACC performance further and has been integrated within zeroRISC's research fork on PQC for open-source silicon. The implementation of side-channel countermeasures is forthcoming.
This cross-posting is courtesy of our collaborators at the Max Planck Institute for Security and Privacy (MPI‑SP). Authored by Amin Abdulrahman and Hoang Nguyen Hien Pham, we are sharing it because it informs our high‑performance embedded post‑quantum solution. It clearly lays out some of the design considerations for the transition to post-quantum safety and high quality set of solutions. We’re grateful for the collaboration and look forward to sharing more PQC results in forthcoming posts.
TL;DR: We describe extensions based on the OpenTitan Big Number (OTBN) coprocessor to enable very efficient support for recently standardized lattice-based post-quantum crypto systems, achieving speed-ups of a factor of 6--9x compared to the baseline. The resulting extended design for an Asymmetric Cryptography Coprocessor (ACC) and software implementations targeting the same are open-sourced and slated for adoption by GlobalPlatform's Trusted Open Source Silicon Task Force. Follow-up work has improved ACC performance further and has been integrated within zeroRISC's research fork on PQC for open-source silicon. The implementation of side-channel countermeasures is forthcoming.
The world of security has been and still is observing two paradigm shifts:
- The transition to post-quantum cryptography
- The realization that open source leads to more secure products
The Imminent Need for Practical Post-Quantum Cryptography
Today's widely deployed asymmetric cryptography is at risk: Schemes such as RSA and elliptic-curve cryptography (ECC) are susceptible to attacks using powerful quantum computers, once those become available. Although this threat might be years---or even decades---away, it was essential that the cryptography community, companies, and standardization bodies started acting as early as possible. The reason for this are so-called "Harvest Now, Decrypt Later" attacks in which a (large-scale) adversary may intercept today's communication that is believed to be secure with the intent to decrypt it once a sufficiently powerful quantum computer becomes available.
As a consequence, in 2016, NIST launched a new standardization effort---modeled after its earlier AES and SHA-3 competitions---to identify cryptographic algorithms that run efficiently on today's hardware while remaining secure against future quantum adversaries. This field is known as post-quantum cryptography (PQC).
The release of the final NIST standards for three PQC schemes in 2024 marks a pivotal moment in IT security. The two primarily recommended schemes, ML-KEM (a key encapsulation mechanism) and ML-DSA (a digital signature scheme), are being swiftly picked up by the industry and can already be found in various software, some of which you may even be using! Prominent examples are Google's Chrome browser, Mozilla Firefox, Cloudflare, Signal, and Apple's iMessage.
This growing adoption also signals the importance of efficient and secure implementations of said primitives, including efficient software for devices like smartphones, efficient hardware circuits for items like credit cards, and efficient hardware/software co-designs living in a space in between. However, many PQC schemes like ML-KEM and ML-DSA present significant implementation challenges compared to their relatively simple classical counterparts. Their mathematical structures and operational patterns vastly differ from the classical RSA and ECC algorithms that today's cryptographic hardware accelerators were designed to support. We consider bridging this gap as critical: our work shows that implementations of post-quantum algorithms on "classical" secure hardware/software co-designs are prohibitively slow for production applications.
Therefore, our research addresses a central question for the hardware security community: How can we enable high-performance post-quantum cryptography on existing, general-purpose secure hardware platforms with modest modifications? This question is not only academically relevant but also of increasing practical importance as migration plans for PQC in industry and governments accelerate.
In the remainder of this blog post, you will find out how we solved this question from a technical perspective, explaining our approach and presenting parts of our results.
Open-Source Silicon
Secure hardware is ubiquitous in our everyday lives. It's part of our smartphones and laptops, and some of you might even own dedicated security tokens like a Yubikey or SoloKey. In contrast to cryptographic software implementations, open and publicly auditable hardware is a rarity. The OpenTitan project was the first coordinated effort that aimed to change this by "building a transparent, high-quality reference design [...] for silicon root of trust (RoT) chips" [2], to facilitate trust and security by providing public design access. Open-source silicon projects enable the research we are doing at MPI-SP: We can try, evaluate, and even extend open designs as part of our research and make the implementation and results of our research freely available to generate a real-world impact. We see this shift to openness as a major step in the domain of hardware security, and with chips based on open-source silicon soon becoming commercially available, it has been proven that building a business and open-sourcing your designs are not in contradiction.
Open-Source Silicon as a Platform for PQC Innovation
OpenTitan is a monolithic, RISC-V-based open-source hardware root-of-trust with contributions from many parties [2] and is on track to enter mass deployment in devices such as future Chromebooks [3].
The source codebase has multiple useful, standard cryptographic accelerators. Among these, there is an AES core, a KMAC accelerator that can be used for computing SHA3 and its XOF-mode SHAKE, and most importantly to our work, the big number coprocessor OTBN, specialized for accelerating asymmetric cryptography such as ECC and RSA. Various layered countermeasures against side-channel and fault injection attacks, useful for secure embedded systems, were implemented for this. These include data-path blanking, data integrity protection, and secure wiping [4].
As we transition from classical to PQC, many real-world systems are expected to require hybrid operation---simultaneous use of both classical and PQC---for the foreseeable future, further emphasizing the need for a flexible and extensible hardware approach. Legacy systems will also benefit from this flexibility as an immediate transition to PQC for all applications is not expected.
We took the existing coprocessor, which we refer to as the baseline coprocessor (BC), as a starting point for a more flexible coprocessor. We call our augmented design the asymmetric cryptography coprocessor (ACC), as it adds acceleration for post-quantum cryptography in addition to accelerating traditional asymmetric cryptography. ACC's targeted modifications address specific performance bottlenecks of lattice-based PQC, while preserving the flexibility and extending the security properties of the original design.
Designing the ACC
The BC offers a RV32I-inspired RISC-V instruction set alongside custom big-number instructions operating on 32 registers of 256 bits each. Since it is programmable, extending the instruction set architecture (ISA) is a natural approach to enabling PQC support. We begin by analyzing the performance bottlenecks in PQC software running on BC, then propose a set of ISA extensions for the ACC that mitigate these bottlenecks. Throughout our work, we adhere to the original design philosophy of generality and flexibility rather than overly specialized solutions.
We approach this task in two steps:
1. Profiling Software-Only PQC Implementations on BC
We first developed assembly-level software implementations of ML-KEM and ML-DSA, including most state-of-the-art optimization techniques introduced in previous work. The profiling of this baseline allowed us to identify the two main bottlenecks:
- Hashing (SHA3/SHAKE): The cryptographic hash functions required in both ML-KEM and ML-DSA consumed the majority of execution cycles, often over 50%.
- Polynomial Arithmetic: (modular) multiplications, additions, and subtractions on small, typically 16 or 32-bit, integers, for example, in the Number Theoretic Transform (NTT), were also significant contributors to runtime.
These findings, although consistent with previous research on PQC on other platforms (e.g., Cortex-M4), are particularly pronounced on BC coprocessor, which is optimized specifically for operations on large integers in contrast to high-throughput parallelism over small integers.
2. KMAC Interface & SIMD ISA Extensions for Polynomial Arithmetic
The ACC addresses both bottlenecks through two complementary extensions:
KMAC Interface. We designed and implemented a direct interface between BC and the high-performance KMAC core, allowing cryptographic operations to offload hash calculations securely and efficiently, without exposing the secret state to less protected parts of the system. This change alone enables speedups of more than 5x for ML-KEM key generation.
SIMD Instructions. To address the polynomial-arithmetic bottleneck, we introduced carefully chosen single-instruction-multiple-data (SIMD) instructions into the instruction set architecture. These enable parallel modular addition, subtraction, and multiplication of 16- or 32-bit elements packed within the 256-bit wide registers.
In the following, the .16H option means a 256-bit wide register is viewed as a
vector of 16 16-bit elements, while .8S means 8 32-bit vector elements. m
stands for modular reduction, and l stands for lane mode (explained below).
Our proposed instructions are:
bn.addv{m}{.16H,.8S}: Vectorized addition. Modular reduction is conditional subtraction of the modulusq.bn.subv{m}{.16H,.8S}: Vectorized subtraction. Modular reduction is conditional addition ofq.bn.shv{.16H,.8S}: Vectorized shift.bn.mulv{m}{.l}{.16H,.8S}: Vectorized multiplication. Withm, the Montgomery multiplication is performed. Withl, all the elements of the first source vector are multiplied by one element of the second source vector of a given index.bn.trn{1,2}{.16H,.8S}: Vector transpose. With1, even-position elements of the first and second source vectors are interleaved in the destination vector. With2, it is the same operation, but for odd-position elements instead.
The proposed instructions can be visualized as below:

Proposed Vectorized Instructions
These instructions are well-suited to optimize core routines such as the NTT and base multiplication, which are the most performance-critical routines to ML-KEM and ML-DSA, next to the hashing.
Importantly, unlike prior work that focused on tightly coupled accelerators for specific algorithms resulting in scheme-tailored instructions, the ACC's ISA extensions are generic. They enhance not only ML-KEM and ML-DSA, but are also broadly applicable to a large class of lattice-based and symmetric cryptographic algorithms as long as modular operations are a significant bottleneck. This maximizes the return on hardware investment and supports future cryptographic agility.
Modifying the Hardware for the New Instructions
Now, let us get to the main question: how can hardware costs be kept low for such powerful instructions? The answer is: by intelligently reusing existing resources!
Below is the graph showing the BC pipeline. The purple blocks relate to the RV32I portion of the ISA, while the green ones are related to the big-number ISA, operating on the 256-bit registers. The blue border indicates which block is modified, while the dashed one shows which block is optional.
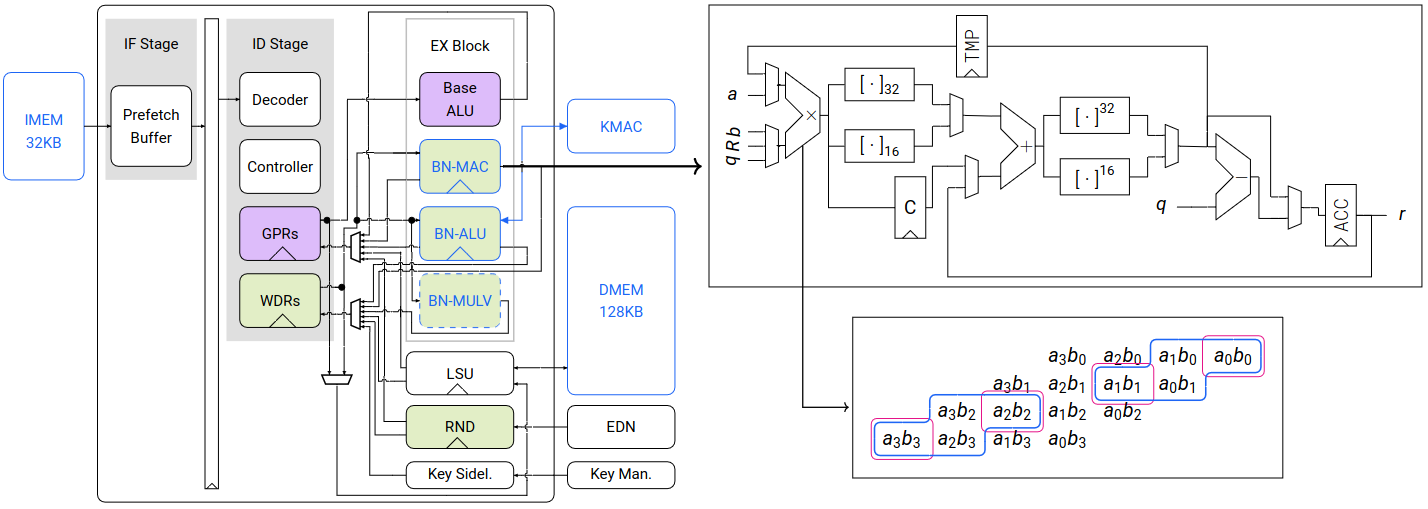
Visualized BC’s Pipeline
For vectorized addition and subtraction, we split the existing 256x256-bit
adder in the BN-ALU unit to 16 16x16-bit adders. From these small adders, 8
32x32-bit, 16 16x16-bit or 256x256-bit sums can be computed depending on their
input carries. For vectorized shift and vector transpose, we reuse the
BN-ALU's functional unit for shifting.
For vectorized multiplication, our main approach was to extend the existing
64x64-bit multiplier in the BN-MAC unit to compute either one 64x64-bit, two
32x32-bit, or four 16x16-bit multiplications by splitting the 64x64-bit product
and combining appropriate partial products. For modular multiplication, the results
are further reduced using Montgomery multiplication, which takes 3 cycles.
Overall, one bn.mulvm instruction takes 12 cycles for computing 16 16x16-bit
(.16H variant) or 8 32x32-bit (.8S variant) modular multiplications.
Similarly, one bn.mulv takes 4 cycles for both variants.
As a design-space exploration, the blue-dashed BN-MULV block in the graph
above represents an alternative for vectorized modular multiplication. While
this significantly accelerates software performance by reducing bn.mulv{m} to
a single cycle, it incurs a substantial increase in hardware cost.
Key Results: ACC's Software Speedup and Hardware Cost
We compared the ACC against our own software implementations on the BC coprocessor and against other PQC projects leveraging OpenTitan IP. We also compared against hardware/software co-designs on different platforms, most of which are less versatile or use scheme-specific accelerators.
The combined effect of the ACC's extensions is substantial:
- Software Performance: With the KMAC interface and our SIMD extensions, ML-KEM and ML-DSA achieve a speedup by a factor between 6x and 9x for different operations and parameter sets compared to the implementation on BC. For example, verifying an ML-DSA signature is not only feasible on the ACC but also faster than verifying an ECC signature at an equivalent "classical" security level (e.g., ML-DSA-44 verification is 41% faster than ECDSA-P256).
- Hardware Overhead: The above speedup in software is achieved with only an increase in cell count of less than 17% for the ACC compared to BC, amounting to less than 3% increase in the area of the full core.
- Side-channel Resistance: The ACC's extensions were implemented with the side-channel countermeasures also present in BC. Along with our collaborators, we will release additional masking or blinding countermeasure implementations in the future.
- Generality and Flexibility: The ACC's SIMD instructions accelerate a wide range of cryptographic primitives. Future schemes (and potential revisions of existing ones) can be supported by software updates, not costly hardware redesigns.
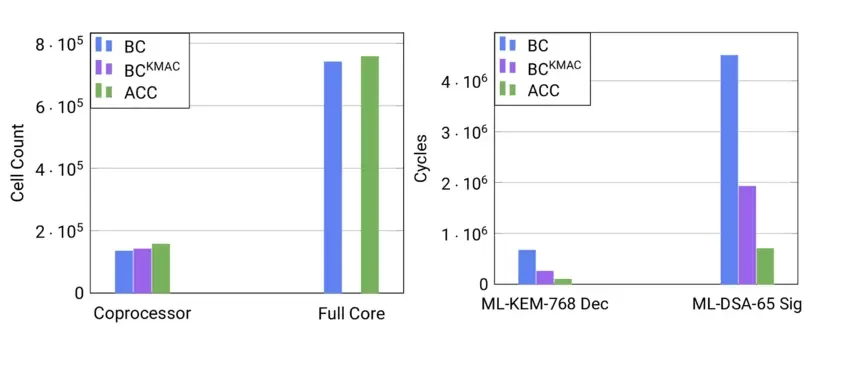
BCKMAC: BC with our KMAC interface. ACC: BCKMAC with our ISA extensions.
In summary, our work on the ACC demonstrates that enabling embedded PQC is not only possible, but also can be achieved efficiently at reasonable hardware cost while retaining flexibility.
Follow-up Work
Since the publication of the paper, several pieces of follow-up work have been carried out, including:
- Stack optimization for ML-DSA aimed at reducing memory consumption, which is critical for lowering hardware cost and for enabling first-order masked ML-DSA on ACC, since masking incurs significant memory overhead. This optimization has been implemented by zeroRISC and is available here.
- "Improving ML-KEM and ML-DSA on OpenTitan - Efficient Multiplication Vector Instructions for OTBN" further improves the current 64x64-bit multiplier to compute all sixteen 16x16-bit multiplications instead of only four. Together with shifting the modular multiplication from hardware back to software through new vector multiplication instructions and better vector adder designs, the authors achieve speedups of up to 17% for both ML-KEM and ML-DSA, while preserving the same area and improving the frequency of the whole design.
- Our work has served as a partial foundation for the approaches and implementations presented in [7,8]. Building on our code base, [7] implements some masking gadgets on BC.
On-going and Future Work
There are still many opportunities for improvements regarding our current design and its interplay with PQC. We are looking forward to continuing this line of work for the following ideas:
- Extending support to other post-quantum schemes (e.g., UOV, MAYO, HQC, Classic McEliece) and hybrid-, and homomorphic cryptography. As long as other PQC schemes heavily rely on modular operations on small integers or on hashing, it is worth exploring the performance improvements by using our ISA extension and the KMAC interface.
- Leveraging new vector instructions for efficient symmetric cryptography, such as SHA-2/SHA-3 variants and stream ciphers.
- Since side-channel attacks are being researched thoroughly nowadays [9,10], a masked implementation of ML-KEM and ML-DSA is of high importance.
- Enabling formal verification for crypto code running on the ACC is also an important next step. For example, re-implementing ML-KEM and ML-DSA in the Jasmin language. Ongoing work by Arranz-Olmos is aimed at enabling this.
Conclusion
The cryptographic landscape is undergoing a rapid transformation with research accelerating for two critical and interconnected areas: post-quantum cryptography and the resilience of its implementations.
The demand for secure hardware PQC solutions highlights the crucial role of open-source silicon initiatives, whose transparency allows us researchers to push innovation and adapt to the evolving challenges.
Our work, while one of many contributions within this larger research effort, directly addresses the potential of open-source silicon. With the ACC, we demonstrate that by strategically equipping open-source silicon designs with versatile and efficient hardware features, it is possible to achieve high-performance post-quantum cryptography. Crucially, we show that these enhancements can be integrated at a reasonable hardware cost.
Finally, we would like to thank all the open silicon contributors out there for pursuing such an amazing idea and shout out to other co-authors and many people involved in this project for their help and feedback.
Craving for more?
If you are interested in this work and want to explore the juicy details, our paper "Towards ML-KEM and ML-DSA on OpenTitan" is published at IEEE S&P 2025. We also uploaded a more detailed version of the paper to the IACR eprint archive. All software and hardware used in this research are made publicly available in our GitHub repository.
For readers who are curious about other approaches trying to bring PQC to open-source silicon, you can check out [5,6]. We also highly encourage you to check out the fantastic blog posts by zeroRISC, major contributors to OpenTitan's original cryptography implementations, on the practical deployment of embedded post-quantum and classical cryptography.
Thank you for reading this very first blog post of MPI-SP!
Please get in touch with us, if you ...
- ... are looking for collaborations on open-source secure silicon.
- ... can imagine writing a Bachelor's or Master's thesis with us on open-source silicon.
- ... would like to work as a student assistant on topics around PQC on open-source silicon, high-performance software implementations, or hardware design.
- ... have any feedback on this blog post and on how we can make our research more accessible to you.
Email:
- Amin Abdulrahman (amin@abdulrahman.de)
- Hoang Nguyen Hien Pham (hoang-nguyen-hien.pham@mpi-sp.org)
References
[1] Amin Abdulrahman, Felix Oberhansl, Hoang Nguyen Hien Pham, Jade Philipoom, Peter Schwabe, Tobias Stelzer, and Andreas Zankl. "Towards ML-KEM & ML-DSA on OpenTitan." In 2025 IEEE Symposium on Security and Privacy (SP), pp. 1-19. IEEE, 2025. https://eprint.iacr.org/2024/1192
[2] OpenTitan. "OpenTitan". https://opentitan.org/
[3] Nuvoton. "Nuvoton Develops OpenTitan® based Security Chip as Next Gen Security Solution for Chromebooks". https://www.nuvoton.com/news/news/all/TSNuvotonNews-000514/
[4] OpenTitan. "Introduction to OTBN". https://opentitan.org/book/hw/ip/otbn/doc/otbn_intro.html
[5] Emma Urquhart and Frank Stajano. "Acceleration of Core Post-quantum Cryptography Primitive on Open-Source Silicon Platform Through Hardware/Software Co-design." In: Cryptology and Network Security. CANS 2024. Lecture Notes in Computer Science, vol 14905. https://doi.org/10.1007/978-981-97-8013-6_7
[6] Tobias Stelzer, Felix Oberhansl, Jonas Schupp, and Patrick Karl. "Enabling Lattice-Based Post-Quantum Cryptography on the OpenTitan Platform." In Proceedings of the 2023 Workshop on Attacks and Solutions in Hardware Security (ASHES '23). Association for Computing Machinery, 2023. https://doi.org/10.1145/3605769.3623993
[7] Filali Hakim. "Power Side-Channel Evaluation and Hardening of PQC Algorithms on OpenTitan." Master Thesis. 2025. https://www.research-collection.ethz.ch/entities/publication/efd66d6b-69ce-4067-b516-fe6d0d5a934a
[8] Pascal Etterli. "Design and Optimization of a PQC ISA Extension for OTBN". Semester Project. 2024. https://lowrisc.org/wp-content/uploads/2025/06/etterli_design_2024_report.pdf
[9] Olivier Bronchain and Gaëtan Cassiers. "Bitslicing Arithmetic/Boolean Masking Conversions for Fun and Profit with Application to Lattice-Based KEMs." IACR Transactions on Cryptographic Hardware and Embedded Systems. 2022, 4 (Aug. 2022), 553-588. https://eprint.iacr.org/2022/158.pdf
[10] Jean-Sébastien Coron, François Gérard, Tancrède Lepoint, Matthias Trannoy, and Rina Zeitoun. "Improved High-Order Masked Generation of Masking Vector and Rejection Sampling in Dilithium." IACR Transactions on Cryptographic Hardware and Embedded Systems. 2024, 4 (Sep. 2024), 335-354. https://eprint.iacr.org/2024/1149.pdf
Fast, Flexible, Future-Proof: The “Cryptolib” Embedded Cryptography Library
This post describes design choices we made in developing the cryptolib embedded cryptographic library.
This post describes design choices we made in developing the cryptolib embedded cryptographic library. Initially developed for OpenTitan, we have added support for upcoming accelerators while maintaining backward compatibility. This post explores how we balanced performance, flexibility, and maintainability, while also highlighting the importance of key development practices like hardware/software co-design.
This library represents countless hours of engineering effort over many years and is the culmination of a series of careful engineering choices designed to serve both developers and integrators for the long-term. We have emphasized modularity and configurability such that it can be flexibly implemented across a variety of devices, aligned with the open-source mentality of reuse and adaptation.
Cryptolib: Cryptography for the Real-World
Cryptolib is the cryptographic library paired to our OpenTitan IP-based set of hardware cryptographic accelerators. Many configurations have a standard RISC-V processor, but also
a hardware key manager, for securely storing keys
hardware accelerators for symmetric operations like AES encryption
and a cryptography coprocessor for asymmetric operations like RSA signatures.
Together, this roughly looks like:
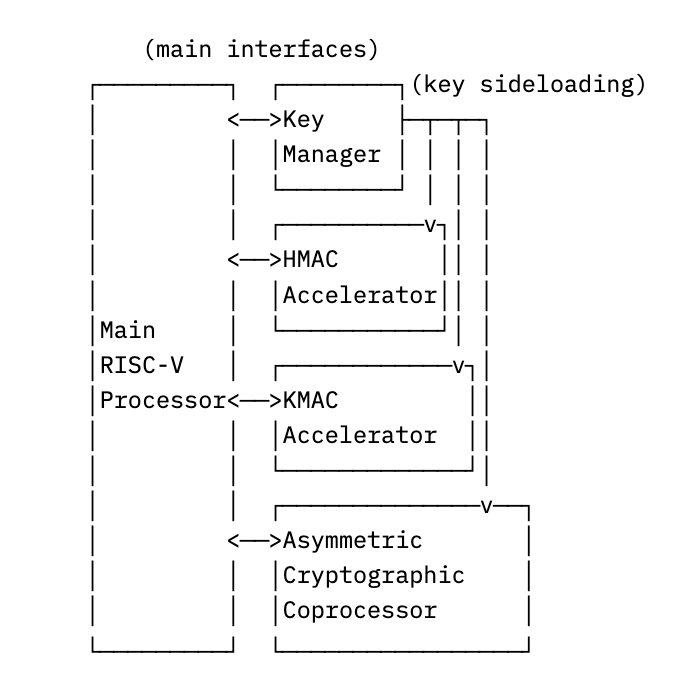
In order to make use of all of the above hardware, cryptolib itself consists of a combination of
Drivers, for controlling each key manager and each hardware accelerator
Coprocessor Assembly, for implementing algorithms on the asymmetric cryptography coprocessor
Main Processor Code, for initializing operations on each accelerator, as well as performing some hardened cryptographic operations (i.e. GHASH for AES-GCM)
As an example of what this looks like in practice, let’s trace what happens when a user requests a single RSA signature.
[Application Code] The code on the main RISC-V processor makes a call to the synchronous cryptolib API, e.g. using otcrypto_rsa_sign, providing the message and appropriate private key for signing
[Cryptolib API] The cryptolib implementation of otcrypto_rsa_sign loads the “RSA sign” program onto the cryptographic coprocessor and copies the provided message and key into the coprocessor memory
[Cryptolib Driver] The cryptographic coprocessor driver triggers the coprocessor to start performing the signature operation
[Cryptolib Coprocessor Implementation] The coprocessor performs the signature and informs the processor of completion
[Return] The processor fetches the signature from coprocessor memory, clears the coprocessor memory, and returns the signature back to the API caller
(Note that while the above directly passes key material to cryptolib for signing, keys can instead be kept in the hardware key manager for increased security, where the coprocessor can fetch them via sideloading.)
In terms of algorithms, cryptolib presently includes support for
AES-128, AES-192, and AES-256 in ECB, CBC, CFB, CTR, OFB, and GCM modes
SHA2-256, SHA2-384, and SHA2-512
SHA3-224, SHA3-256, SHA3-384, and SHA3-512
SHAKE128, SHAKE256, cSHAKE128, and cSHAKE256
HMAC with SHA2-256, SHA2-384, or SHA2-512
KMAC128 and KMAC256
RSA-2048, RSA-3072, and RSA-4096 key generation
RSA-2048, RSA-3072, and RSA-4096 PKCS v1.5 signatures
RSA-2048, RSA-3072, and RSA-4096 PSS signatures
RSA-2048, RSA-3072, and RSA-4096 OAEP encryption
ECDSA with NIST P-256 and NIST P-384 curves
ECDH with NIST P-256 and NIST P-384 curves
Ed25519
X25519
AES-CTR-DRBG with or without a hardware TRNG
HMAC-KDF-CTR
HKDF
and KMAC-KDF.
While extensive, cryptolib has been architected in a way that allows choosing the algorithms you choose to support, allowing it to remain small while usable in a variety of contexts. We’ll discuss this point in detail later.
Lastly, cryptolib also includes a number of features for maintainability, including
A detailed suite of functional test integrated into ZeroRISC’s hardware CI platform
Automated KAT testing against both Wycheproof and NIST CAVP vectors
An extensive simulation and debugging toolchain for the ACC
and more.
To dive into how we maintain such an extensive library, we’ll start with the most exciting part: performance.
Performance: Accelerators, Simulation, and Optimizations
In order to deliver high-performance cryptography, cryptolib takes a heterogeneous approach to acceleration:
Symmetric cryptography like AES encryption often requires high throughput, and implementations are unlikely to change over time, meaning that it’s a good fit for a dedicated hardware accelerator
Asymmetric cryptography like ECDSA can be optimized in clever ways and needs more attention to prevent side-channel leakage, meaning a programmable accelerator makes sense
For symmetric operations handled by dedicated accelerators, traditional hardware cryptography tricks ensure high throughput, though some more recent techniques–such as Domain-Oriented Masking–are critical in mitigating side-channel leakage while maintaining good performance.
In terms of cryptolib, however, such operations are fairly straightforward: the implementation for the RISC-V processor simply loads the appropriate values into the appropriate MMIO (memory-mapped input/output) registers, triggers the operation, and fetches the results upon completion. For instance, the cryptolib AES driver:
Ensures that the AES accelerator has access to entropy for masking, via a MMIO read
Writes the following into AES accelerator MMIO registers:
whether to encrypt/decrypt
whether to use a sideloaded key
the cipher mode
the AES key to use
and the initialization vector to use
Alternately (1) reads ciphertext blocks out from the accelerator and (2) writes new plaintext blocks to the accelerator as provided through the cryptolib API, also via MMIO
Reads the IV back to confirm it hasn’t changed, and clears the AES accelerator internal state via a MMIO write
More interesting are cryptolib’s implementations of asymmetric operations, where the code loaded onto the cryptographic coprocessor can undergo significant optimization. For an in-depth analysis of a large optimization with ~3x performance gain, see Part 1 and Part 2 of our recent exposition on optimizing RSA using Chinese remainder theorem modular exponentiation.
As a self-contained example of making cryptolib performant, we can review our Ed25519 elliptic curve signature implementation for the cryptographic coprocessor. Algorithms such as Ed25519 are defined by a set of immutable steps that any implementation has to follow, so at first glance, it might not seem like there’s much room to optimize. For instance, Ed25519 dictates that a signer must:
Compute a SHA-512 hash on their private key and split the result in half
Multiply an elliptic curve point by the first half to get the public key
Compute a SHA-512 of the second half concatenated with the message
Multiply an elliptic curve point by the result
Compute a SHA-512 the output of that with the public key and the message
etc.
Most of the room for improving performance instead comes from how these base operations, such as hashing or elliptic curve point multiplication, are implemented. We’ll start with hashing: given what we know about the Ed25519 implementation, we might consider something like the following:
Have the main processor delegate as many SHA-512 operations as possible to a hardware accelerator before needing to perform an elliptic curve operation
Have the main processor take the results and load them into the cryptographic coprocessor, which will perform as many of the elliptic curve operations as possible on the results
Have the main processor take those results and perform what SHA-512 hashes are needed
etc.
While this seems like a straightforward approach, it adds a remarkable amount of overhead by requiring constant data movement through the processor as well as starting and stopping the cryptographic coprocessor. Additionally, this approach makes for a more complex security analysis, as various intermediate values from the operation travel across internal buses when computing a signature.
Instead, we might consider implementing a SHA-512 implementation in the cryptographic coprocessor itself. While it may not have the throughput of the dedicated hardware accelerator, it has low enough latency to make it the better approach for Ed25519 signing: see here for our internal implementation, which makes extensive use of wide register operations to efficiently manage SHA-512 lanes while minimizing code size.
Now, rather than now having to call back to the main processor, SHA-512 hashes can be computed using function calls to sha512_init, sha512_update, and sha512_final as follows, with all state maintained within the coprocessor:

As for the elliptic curve operations, these offer even more room for optimization, down to the arithmetic level. Since the logic of Ed25519 requires multiple elliptic curve operations, and each elliptic curve operation in turn requires many arithmetic operations, shaving even a few cycles off these base operations can result in remarkable speedups.
For instance, one frequently-used core operation is multiplication mod p, where p is the Ed25519 prime 2^255 - 19. Naively, one could simply multiply two 255-bit numbers together, and then use long division to get the remainder mod p, but in practice this is fairly slow. Faster modular reduction tricks, such as Barrett reduction, do exist and are necessary at points, see our implementation for the Ed25519 scalar field here.
But we can do even better than that by realizing that p = 2^255 - 19 is so close to a power of two (for the mathematicians, a pseudo-Mersenne prime). Pretend we have two numbers a and b mod p, which we can split into four 64-bit chunks:
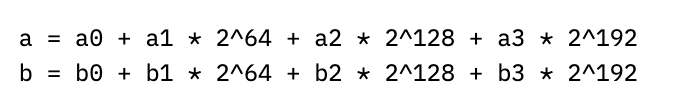
If we multiply out a times b, we’ll get

where the ellipses contain terms multiplied by 2^256 and higher. Since we want to work mod p though, we can note that 2^256 mod p = 38, so that e.g. a1b3 * 2^256 “wraps around” and just becomes 38*a1b3. If we continue this “wrapping around” process by reducing each power of 2 mod p, the columns of coefficients above start to look like (with multiplier on top of each column):
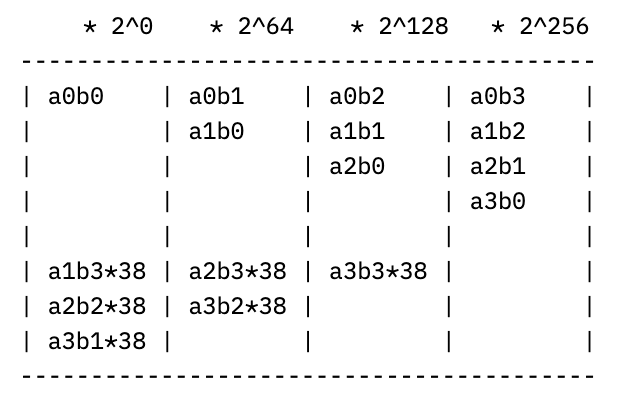
meaning we can just compute these smaller, 64-bit partial products instead, an operation which the coprocessor has dedicated instructions for. While this will work as-is–computing each partial sum, adding them together, and then addressing the carry-out from the last column–we can do even better by eagerly addressing this last part.
Rather than addressing the carry-out last, we can pre-compute the partial sums of the right two columns, wrapping around the result and adding it to the left two columns. This looks like computing a new value for the right two columns
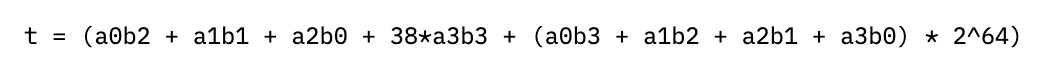
which splits into four 64-bit chunks t0-t3 as before, resulting in the updated columns of:
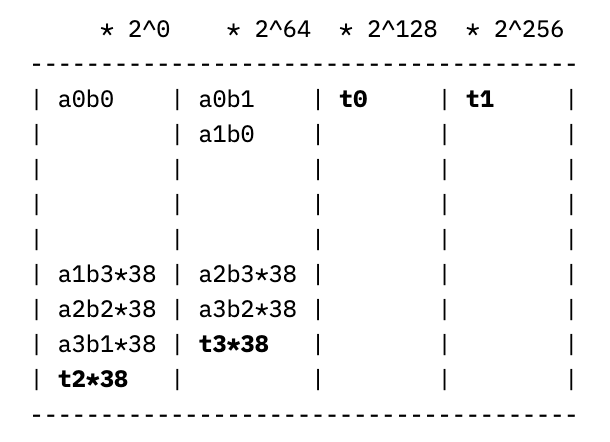
allowing the results in the left and right columns to be added at the end with a single conditional subtraction of p. Making strong use of the cryptographic coprocessor’s instructions for wide register shifts and computing 64-bit partial products, this allows for modular multiplication in a mere 24 cycles, significantly speeding up the elliptic curve operations built on top of it. For comparison, the Barrett reduction we use for the scalar field takes 73 cycles per modular multiplication, and a generic constant-time bignum division that is not specialized to the divisor takes about 15,000 cycles for 256-bit operands. These saved cycles truly count; the modular multiplication is called about 7,000 times per signature. If we used Barrett reduction for the coordinate field, then the entire signature routine would be more than 2x slower.
Of course, when implementing such complex optimized routines, especially in assembly, the risk of implementation mistakes goes up. Especially for modular reduction routines, some instructions are no-ops except in very specific cases, so it is easy to omit them or miss bugs (arithmetic bugs like this have been found, among other places, in modular reductions from well-established cryptographic libraries like openssl, go/crypto and TweetNaCl). To ensure functional correctness, we rely on techniques beyond testing for critical and complex routines like this one. We implemented a full model of the coprocessor within the proof assistant Rocq and verified the exact code for 25519 modular reduction in fact computes modular reduction for all inputs. Formal tools like Rocq allow us to cover the entire cryptographically-large input space for high-risk routines like this, rather than relying on luck to hit rare cases in random testing. Our P-256 modular reduction is also verified against an ad-hoc earlier prototype of the coprocessor model, and the Ed25519 scalar reduction is verified at an algorithmic level (these other proofs predate the updated model and are not yet ported).
By using techniques like these which carefully leverage the instruction set of the coprocessor, as well as employing techniques such as hardware/software co-design (more on this in a future post), we can provide highly performant cryptographic implementations with no cost to flexibility or maintainability.
Flexibility: Modular Design and Testing
While performance is exciting, it’s worth little if the implementation in question won’t work for your application. Embedded cryptography is a critical component in devices of all scales, from the smallest secure element to a fully-featured baseboard management controller in high-end servers. Each application comes with different kinds of onboard hardware, available memory, and requirements in terms of algorithms and their performance.
Rather than try to write a bespoke, separately-verified cryptographic library for every possible device, our aim with cryptolib is to allow for easy tailoring to a myriad of different possible configurations. As part of this effort, we’ve put careful work into separating out different cryptographic APIs to allow easy customization for any deployment.
For instance, if an application only called for ECDSA P-384 for firmware signatures and TLS v1.3 with the TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384 ciphersuite, then ideally one would only want
Dedicated hardware accelerators for AES and SHA-384
A cryptographic coprocessor with programs for P-384 ECDSA and ECDH
Drivers and APIs for both accelerators and the coprocessor
as anything else would just waste die area or storage. By carefully putting effort into modularizing cryptolib, e.g. by separating out the SHA2 and SHA3 APIs, we ensure cryptolib can be flexibly configured by integrators who select exactly which parts of the cryptographic hardware and cryptolib they need for their application, letting them reap all of the benefits of a single carefully-maintained cryptographic library while also providing an end-product that works with their constraints.
As part of making this single cryptolib useful in any configuration, the testing suite is similarly modularized, allowing for easy regression testing of any integration. Additionally, we’ve put extensive effort into maintaining a test framework to run both NIST CAVP and Wycheproof known answer tests (KATs), easing certification for integrators and allowing them to maintain confidence of correctness. For instance, after we performed the RSA CRT optimization, we put extensive effort into ensuring that everything passed the appropriate RSA KATs to be confident our optimizations were correct.
By keeping the design modular and continuously verifying implementations against a wide suite of functional tests and KATs, we’re able to keep cryptolib ready to distribute with confidence in any number of applications.
Maintainability: Tooling, CI, and Documentation
The last pillar of our cryptolib strategy to highlight is maintainability, as keeping a maintainable code base is essential to any auditing, certification, or further optimization effort.
A large part of keeping software maintainable is catching problems early. Alongside the functional tests and KATs which we check in both on-push and weekly CI jobs, cryptolib contains a wide array of additional tooling for the cryptographic coprocessor, from a full cycle-accurate simulator to detailed static analysis tooling, e.g. for ensuring the code is still constant time after each change.
One excellent example of static analysis tooling providing maintainability comes from our process of checking cycle counts. When defending against fault injection, one trick that can be helpful is to count the number of cycles an operation should have taken and compare it against how many it actually took. Unfortunately, the expected cycle count for a program can sometimes be a range of possible cycle counts, and the upper and lower bounds can take a bit of manual labor to compute.
Rather than manually maintaining this range, we instead put a significant effort into static analysis tooling to compute these ranges for us, inserting them at build-time into auto-generated C headers which cryptolib uses to check cycle counts after coprocessor operations.
To set this up, all that’s needed is a simple HJSON file containing the assembly labels corresponding to different “modes” that the coprocessor can be launched in, e.g. for keygen/signing/verifying:
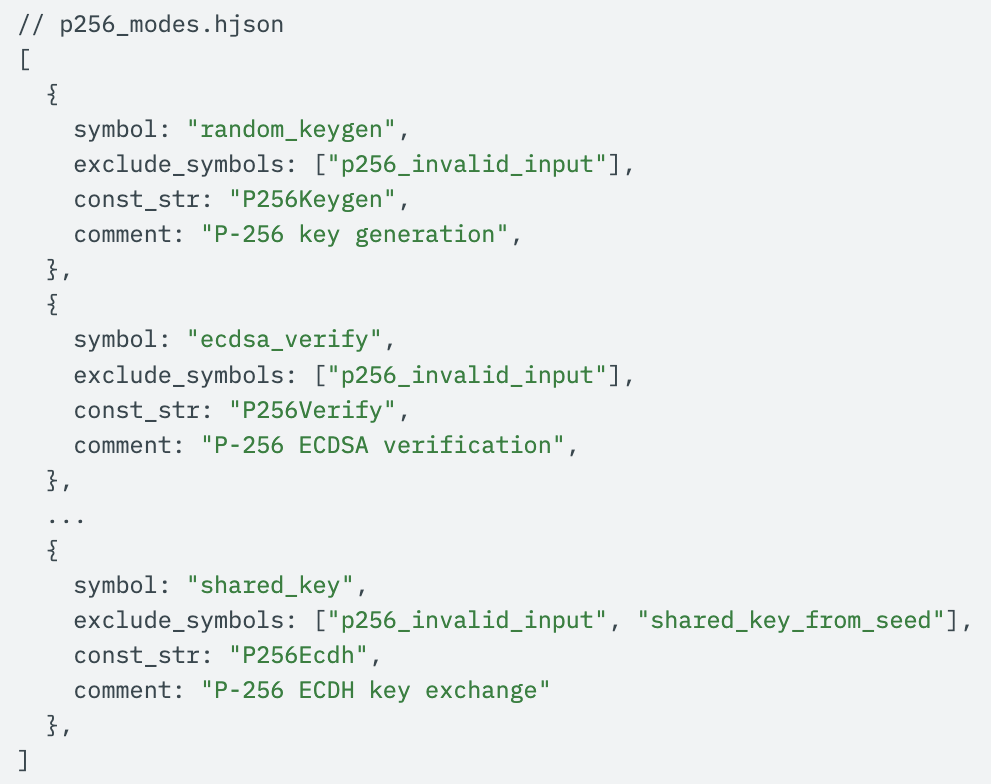
Note that you can also exclude failure control paths, such as those going through the label p256_invalid_input: the static analysis tool will automatically prune these during its pass.
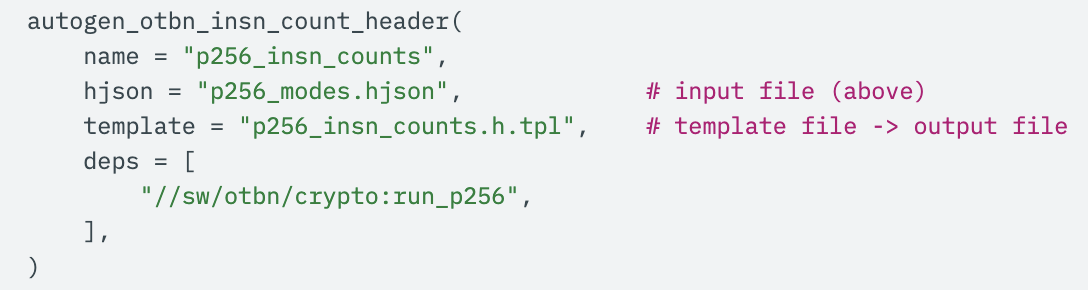
From there, a single Bazel rule results in the autogenerated C header, complete with ranges of possible instruction counts: merely adding
along with a basic header template is all it takes. Underneath the hood, a full static analysis script parses the generated run_p256 top-level P-256 ECC executable, tracing the control flow graph and using various tricks from compiler design to efficiently propagate instruction count bounds through the end of the program.
From there, checking the instruction count is trivial; by adding a simple macro to the coprocessor driver we can–with just one line of C added!–mitigate fault injection attacks via automatically checking the instruction count against the possible cycle count ranges derived at build-time, even for routines that are not constant-time. Tooling like this allows developers and downstream integrators to work efficiently and focus on delivering a secure, performant product.
As a last note regarding maintainability, cryptolib is designed to prioritize documentation first. Docs are automatically generated for the cryptolib API with full descriptions of each operation, and we have placed heavy emphasis in the code on ensuring that all optimizations and design choices are well-documented for future developers. Assembly for the cryptography coprocessor is documented not only with input and output registers for each operation, but also with detailed descriptions of side-effects, usage details, and exactly which registers and flag groups are clobbered. As an example, our RSA modular multiplication routine is documented with all of the following:

These details are invaluable when working on the coprocessor assembly, as cryptographic engineers often have to balance thinking on at several levels at once: the mathematical level where the cryptography takes place, the implementation level where such operations are reduced to algorithms, and the machinic level at which those algorithms become individual instructions. While these may seem like discrete, separable layers, real-world cryptographic implementations can lead to deeply-ingrained interactions between all three. For instance, hardware constraints can affect which algorithm-level approaches are viable, and the small changes in the choice of e.g. a finite field modulus can wildly change what arithmetic looks like at the instruction-level.
In this sense, cryptographic engineering is rhizomatic: its ‘layers’ don’t form a simple stack, but are inextricably, densely linked together. This makes for a significant cognitive load, and easing it with clear documentation can prevent mistakes before they happen while reducing the effort it takes to deliver a high-assurance cryptographic library.
In the future, we plan to automatedly check this metadata via build-time scripts, providing the user with a warning when the clobbered registers/flag groups are out of sync with the code, or when a caller attempts to use the value in a register clobbered by a callee. With thoughtful efforts like these, we aim to ensure even highly-optimized routines remain workable indefinitely.
Conclusion: Cryptolib as a Source of Best Practice
Cryptolib as an embedded cryptography library has been built from the ground up with performance, flexibility, and maintainability at the forefront.
By simultaneously prioritizing these features through continuous effort and engineering expertise, we open the possibility of a high-assurance cryptographic library that not only adapts fluidly to new integrations while providing excellent performance, but also ensures that long-term maintenance and certification efforts are reasonable.
This means that the same cryptographic library can run on RoTs from those in the smallest IoT devices to the largest server baseboards, all while providing a smooth experience for developers and integrators.
If you’re interested in learning more about our approach to maintainable, production-grade cryptography, or hearing about ZeroRISC in general, sign up for our early-access program or reach out at info@zerorisc.com.
RSA with CRT Part 2: Implementing Fast RSA
This post is the second in a two-part series about recently implemented optimizations to speed up performance of our open-source, embedded RSA implementation. Read part one here. This post will cover the actual implementation of RSA CRT key generation and modular exponentiation. Our implementation focuses on correctness, maintainability and performance.
This post is the second in a two-part series about recently implemented optimizations to speed up performance of our open-source, embedded RSA implementation. Read part one here.This post will cover the actual implementation of RSA CRT key generation and modular exponentiation. Our implementation focuses on correctness, maintainability and performance.
Now that we have a sense of the math behind RSA CRT, we might wonder what a practical implementation looks like. Besides correctness, real RSA implementations need to contend with practical matters like limited compute resources, long-term maintainability, and certifiability under essential cryptographic standards such as FIPS 140-3.
We’ll cover not only the path to implementing CRT modular exponentiation itself, but also the fine technical details of working with limited memory and high register pressure while remaining performant and avoiding timing side-channels.
While performance is essential for any deployed cryptographic implementation, certifiability is also critical, as standards like FIPS can are often important requirements of commercial opportunities. As such, we’ll highlight the technical nuance in how we maintained FIPS-compatibility while performing this significant optimization.
To get a sense of what such a performant, certifiable, and maintainable implementation might look like, let’s analyze our implementation of the CRT optimization for RSA in depth, starting with the changes to key generation.
CRT Key Generation (or, Working with Too Little Memory)
The first step is changing the private key format. In naive RSA implementations, the private keys only need to store the modulus n and the private exponent d, as they just compute ciphertexts/signatures as c = md mod n directly.
For RSA CRT, we instead work directly with the primes p and q, and need to store the precomputed values dp, dq and qinv. This takes us from a private key format (for RSA-2048) of
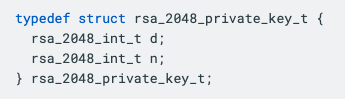
to a new CRT format of

Note that we’re now storing five 1024-bit numbers instead of two 2048-bit numbers, so there is an associated 25% size increase to public keys. Since this represents a change in the ABI, as well as an increase in keyblob sizes, it’s essential for changes like this to be made prior to the initial release of a cryptographic library, preventing reverse compatibility breakages that could have severe impacts on users.
Along with changing the key format, we also need to change the key generation routines to output the values (p, q, d p , d q , q inv ) instead of just (n, d). When writing programs for our asymmetric cryptography accelerator (based on the OpenTitan BigNum implementation), we start by carving up the data memory (“dmem”) into the regions that we’ll be using for storage of different values. Depending on the generation this data memory can be as small as 4 KiB. Previously, the data memory allocation looked like:

(Some parenthetical details: the rsa_cofactor buffer is for inputting a cofactor (either p or q) to reconstruct a RSA keypair; this is handy for importing keys. The mont_m0inv and mont_rr buffers are precomputed constants for Montgomery multiplication, a fast modular multiplication algorithm that helps speed up the generation of primes p and q.)
Now that we also need to compute d p , d q and q inv , as well as track other intermediate values, our new dmem memory map looks like (overlapping buffers shown as sub-bullet points)

which just barely keeps the data memory overhead small enough to allow e.g. for the auxiliary buffers that tests use. Note that some buffers are used multiple times; for instance, the Montgomery constant aren’t used after computing p and q, so we can reclaim that space for storing d later in the key generation routine.
The careful eye might catch two lines above that look somewhat silly; why are dedicated buffers rsa_pm1 and rsa_qm1 needed for storing p - 1 and q - 1? The answer is that the least common multiple function overwrites its inputs to reduce dmem overhead. If we just subtracted one from rsa_p and rsa_q in place, as the prior key generation code did, the LCM computation would clobber the primes in each buffer, resulting in garbage values for p and q in the generated private key.
Next, let’s look at the actual changes to the algorithm. The prior key generation approach looked something like
- Generate random primes p and q
- Compute n = p * q
- Compute lcm(p - 1, q - 1)
- Compute d = e-1
mod lcm(p - 1, q - 1)
- We always take e = 65537 here
- Check that d is ‘large enough’, if not, start over
Here, ‘large enough’ for d means large enough to prevent methods like Wiener’s attack or the Boneh-Durfree attack from recovering the private key. The latter attack works for d < n0.292 , so for safety, NIST SP 800-56B–necessary for FIPS certification–requires that d should be at least half the RSA size in bits.
To convert the above to CRT, we now have to add steps for computing our additional values. We also move our computation of n to the end to allow use of rsa_n as an additional working buffer when computing dp and dq; this has the nice side effect of shaving a few cycles when d isn’t sufficiently large the first time.
- Generate random primes p and q
Compute n = p * q- Compute (p - 1) * (q - 1)
- Compute d = e-1 mod lcm(p - 1, q - 1)
- We always take e = 65537 here
- Check that d is ‘large enough’, if not, start over
- Compute dp = d mod p - 1
- Compute dq = d mod q - 1
- Compute qinv = q-1 mod p
- Compute n = p * q
The computation of dp and dq are straightforward, but computing modular inverses can be tricky to do securely. One thing to watch out for is that the runtime of the modular inverse doesn’t depend on the inputs; otherwise, an attacker could time how long the algorithm takes to run, and leak bits of the key. While this sounds highly theoretical, it was actually the basis of the recent EUCLEAK attack which allows unauthorized cloning of smartcards and FIDO keys.
In our implementation, we make use of the constant-time binary extended Euclidean algorithm (EEA) from BoringSSL, as formally verified by David Benjamin in the fiat-crypto project. Rather than try to perform long division each step like in the typical extended Euclidean algorithm, this binary EEA shuffles intermediate values around to only require division by two, which can be performed with a simple bit shift.
Like the traditional EEA, however, the binary EEA does require a lot of memory. For everything to fit properly in dmem, we make extensive use of not-in-use buffers as scratch space for computations. For instance, when computing qInv with the EEA, we use all of tmp_scratchpad, rsa_d, and rsa_cofactor for a cumulative 1.25 KiB of scratch space.
As a last wistful note, the particularly keen reader might wonder whether we could get away without computing d = e-1 mod lcm(p - 1, q - 1); after all, we immediately reduce it mod p - 1 and q - 1, so it should suffice to compute dp = e-1 mod p - 1 and dq = e-1 mod q - 1 directly.
While this would be a nice trick, we do need to check that d is sufficiently large as part of FIPS compliance, and there’s no practical way short of computing d to determine this. The CRT does guarantee that given d mod p - 1 = dp and d mod q - 1 = dq we can recover a unique d modulo lcm(p - 1, q - 1); this is left as an exercise to the reader (hint: apply CRT to p - 1 and (q - 1) / gcd(p - 1, q - 1)) and suggests the following possible approach:
- …
- Compute dp = e-1 mod p - 1
- Compute dq = e-1 mod q - 1
- Compute k = (q - 1) / gcd(p - 1, q - 1)
- Recover d from dp, dq mod k
- Check that d is ‘large enough’
- …
but to our knowledge this hasn’t shown up in practice, as it’s more than likely the overhead from the computation of k and CRT reconstruction outweighs any benefits.
CRT Modular Exponentiation (or, Working with Too Few Registers)
When running the CRT modexp, we expand from a simple call to the square-and-multiply routine to the following:
- Compute mp = m mod p
- Compute cp = (mp)^(dp) mod p (square-and-multiply)
- Compute mq = m mod q
- Compute cq = (mq)^(dq) mod q (square-and-multiply)
- Compute c = q * ((cp - cq mod p) * qinv mod p) + cq
While this looks like a fairly straightforward series of operations, first note that we’ve rearranged mq to only be computed once cp is complete; this is because we don’t have sufficient memory to store mq across the first square-and-multiply call. In fact, the result of the modular exponent overwrites the buffer storing of dp, as we need every other bit of buffer space to compute cq after and dp isn’t used again.
Fortunately, once we reach the CRT reconstruction step, a number of buffers free up for use. Things become fairly straightforward, and we use a simple conditional addition and binary long division for the last two reductions mod p. (We certainly could modify the square-and-multiply function to output cp and cq in Montgomery form, but for simplicity we simply do these last two operations outside the Montgomery domain.)
Memory space isn’t the only limited resource when writing assembly for embedded targets like this cryptographic accelerator; the other difficulty can be running out of available registers.
The accelerator has 32 32-bit general purpose registers available, and when running the existing modexp routine, 20+ of those get overwritten with working values. On top of this, the CRT modexp routine needs to take in 12 input registers containing pointers to memory for output. At first glance, this seems to be a hopeless situation: we don’t have enough registers for inputs and working values together.
This is a situation that compilers run into frequently. When you compile a program from a higher-level language and the number of registers needed approaches the number of total registers, it can be difficult to assign values to registers in a way that keeps the values around for long enough. This phenomenon is called “register pressure,” and the process of assigning values to registers is called “register allocation”; higher register pressure makes register allocation difficult to impossible.
To address this, compilers will typically handle high register pressure with “spilling,” where the compiler inserts instructions to stash some register values in memory, loading the values back into registers once they’re needed. This isn’t ideal though, as it incurs a performance penalty and may expose sensitive values if attackers can snoop on the memory bus.
Fortunately, when hand-writing assembly, one can often avoid spilling to memory by a bit of register gymnastics. By shuffling values out of registers which get overwritten (or “clobbered”) before a section of code, and then restoring them as needed, we can get the correct values where we need them without incurring a significant performance hit.
As an example, here’s where we compute cp = c mod p by calling the pre-existing square-and-multiply algorithm:

Here’s the same routine in pseudocode, for simplicity:
Copy register x4 -> x14
Copy register x3 -> x4
…
Call square-and-multiply routine
Copy register x4 -> x3
Copy register x14 -> x4
Here, the register x14 is used as an input to modexp containing the pointers to the base, exponent, and modulus respectively. x3 and x4 contain pointers to important working buffers, and modexp clobbers 20+ registers, including x3.
At this point in the program, there aren’t any remaining registers which are left over to hold the value in x3. Fortunately, modexp doesn’t overwrite the input register x14, so we can actually use x4 as storage, retrieving its value after the function call. In other words, we shuffle
x14 <= x4 <= x3,
call the buffer, and then shuffle back the values as
x3 <= x4 <= x14
restoring x3 and x4 in a situation where it looked like we were out of registers. Because the register pressure is so high throughout the bulk of the modular exponentiation routine, this required precise attention to exactly how registers could be rearranged to avoid spilling.
Security and Maintenance Considerations (or, Working with Too Many Details)
To keep such code maintainable as well as performant, we carefully document the values stored in each register throughout the code, and at the top of each method maintain
a list of input and output registers, including buffer sizes
a list of all registers clobbered by the routine
a list of all CPU flags potentially overwritten
as well as any additional function-specific details needed by a caller. For instance, at the top of the modular inversion routine used to compute qinv = q-1 mod p, we have the following doc comment:

which informs a caller that any values in registers x2 to x6, x31, or w20 to w26 should be moved elsewhere before calling. Part of maintaining assembly for a cryptographic coprocessor (and frankly, any cryptographic code!) is meticulously ensuring that documentation like this is kept up to date. One future task we’d like to tackle is adding further linting checks to ensure such information keeps in sync with the code.
Automated checks can be invaluable in developing software, especially when security is a concern. As an example, a basic mechanism was built into the legacy codebase for verifying that a provided function is constant time, guaranteeing safety from simple timing attacks.
One approach to check whether a function is constant time is to run it on a bunch of random inputs and compare the number of clock cycles each time. While this can be useful for proving a function isn’t constant time, it can’t prove a function is constant time unless it ends up trying every single possible input. Instead, the aforementioned mechanism doesn’t run the code at all: it scans the assembly itself and builds out a graph of the control flow of the program, inspecting what makes the program flow from one node to the next.
As an example, a toy Python program like

would have a control flow graph of
Each point in this graph is a commented point in the program above, and each edge is a part of the program that could run next. If there’s multiple places a program could go (e.g. an if statement), we label the edge with the condition for it being taken.
By inspecting this graph, we can see that there is one edge that depends on the secret value we provide our function. This corresponds to the if secret == 0: break part of the program, where we exit the loop early if our secret value becomes 0. Indeed, if our secret value is any integer from 1 to 10, then the loop will exit early and an attacker timing the function would be able to detect this. The constant-time check script uses this principle to show that functions are constant time as part of the standard test suite. To allow testing alongside all the other crypto tests, a otbn_consttime_test Bazel rule allows for detailing exactly which routines and sensitive values to trace on every test suite run.
Conclusion
Cryptography can be delightfully infuriating in the way that a cryptosystem expressed in just a few lines of math can require thousands of lines of careful, reasoned code changes to implement properly. Details like performance, maintainability, side channel protections, backwards compatibility, memory and register limitations, and testing implications all must be front-of-mind for the engineer when implementing these systems.
Fortunately, with a combination of careful resource utilization, detailed documentation, clever tooling, and a bit of perseverance, we can find ways to sustainably squeeze out additional performance in even the most resource-constrained systems.
If you’re interested in learning more about our approach to maintainable cryptography, or how ZeroRISC is democratizing access to secure silicon, sign up for our early-access program or drop us a line at info@zerorisc.com.
RSA with CRT Part 1: Speed up RSA by 3x with This One Simple Trick
This post is the first of a two-part series describing recent improvements to make our embedded RSA software (originally developed in the OpenTitan codebase) production ready, leading to a huge speedup for core operations.
This post is the first of a two-part series describing recent improvements to make our embedded RSA software (originally developed in the OpenTitan codebase) production ready, leading to a huge speedup for core operations:
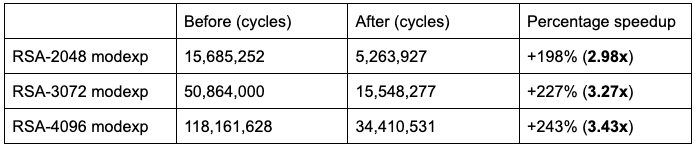
Note: This is the full-length modular exponentiation that forms the core of signing and decryption operations in the RSA cryptosystem. Top-level speedups for signing and decryption are similar.
In this post, we’ll go over the mathematical basis for this standard optimization. In the second part, we’ll go deeper into implementation details and share what a major, specialized, pure-assembly code change looks like in practice.
The Chinese Remainder Theorem
The technique used is ancient, originating in the 3rd century work of mathematician Sun Zi, with a complete theorem dating back to 1247. It states that, if a set of integer moduli n0…nk-1 is pairwise coprime (meaning that the GCD of any pair is 1), then any set of residues a0…ak-1 from those moduli has a solution x such that x is equivalent to every ai modulo ni, and furthermore that the solution x is unique modulo N = n0 * … * nk-1.
This theorem enables us to translate a problem modulo N into a problem modulo factors of N, without introducing ambiguity or multiple solutions. Operations like multiplication modulo large numbers scale more than linearly with the bit-length of the modulus, so doing an operation twice modulo two half-size factors is significantly faster than doing the same operation once with one full-sized value. This is the fundamental property we used to speed up RSA – a standard technique today, but non-trivial to implement in new cryptographic libraries.
The RSA Cryptosystem
RSA was first described in 1977 and is one of the first cryptographic schemes that could operate using separate public and private keys (as opposed to requiring that the people communicating with each other have a previously shared secret key). It’s one of the oldest algorithms that’s still considered secure and in widespread use, whose remarkable endurance can be attributed to its elegant mathematical simplicity.
The core of the algorithm fits in just a few lines (eliding a couple of details, see IETF RFC 8017 for a more formal and authoritative description):
- Choose a fixed, public exponent e. It can be anything, but popular choices for efficiency include 3 and 65537.
- Randomly generate two prime numbers p and q. Their product, n = p * q, combined with the exponent e, is your public key. The bit-length of n determines the “RSA size”; RSA-2048 means that p and q are 1024 bits each and n is 2048 bits.
- Compute the inverse of e modulo lcm(p - 1, q - 1); that is, find a number d such that e * d mod lcm(p - 1, q - 1) = 1. This integer, d, is your private key. Without knowing p and q, it’s not feasible for someone else to compute it.
- To encrypt a message, add padding according to your chosen scheme (e.g.OAEP) to get an integer m representing the message, and compute the ciphertext c = me mod n.
- To decrypt the message, the recipient computes m = cd mod n.
This works because (me)d mod n = med mod n, and ed mod lcm(p - 1, q - 1) = 1. Therefore, med is congruent to mk * lcm(p - 1, q - 1) + 1 modulo n, p, and q. By Fermat’s Little Theorem, we know that since p and q are prime, any number raised to a multiple of (p-1) is equivalent to 1 modulo p, and similarly any number raised to a multiple of (q-1) is equivalent to 1 modulo q. We can therefore cancel out the k * lcm(p - 1, q - 1) factor of the exponent both modulo p and modulo q, and conclude that med is equivalent to m modulo p and also modulo q. By the Chinese Remainder Theorem (hello again!) we know that this means med mod n = m, the original message.
This scheme works for signatures too. An RSA signature uses the same underlying modular operations as encryption; to sign a message, the signer creates a signature s = md mod n and the verifier checks it by computing se mod n and checking that the result is equivalent to the message. Essentially, signing uses the same operation as decryption, and verifying uses the same operation as encryption.
Of the RSA operations:
Encryption and verification (exponentiation with e) is generally very fast, since e is public and small.
Signing and decryption (exponentiation with d) are usually much slower, since d is large and must be kept secret.
Key generation is usually extremely slow compared to either of these, and especially compared to more modern public-key schemes based on elliptic curves. Picking random primes is not easy!
RSA with CRT
The above description of RSA is mathematically accurate, and it’s what our initial implementation in the prior codebase computed. However, if you look at RFC 8017 or most performant RSA implementations, you’ll see a lot of references to “CRT” and numbers like dp and dq that don’t appear here. This is because most production-quality implementations use the Chinese Remainder Theorem (CRT) to translate expensive RSA operations mod N into operations modulo p and q.
Here, we’ll dive into the high-level mathematical description of implementing RSA with CRT. In the next blog post, we’ll describe implementing each part of this description on an asymmetric cryptography acceleration, the critical part of a hardware root of trust which handles performing cryptography such as RSA.
First, let’s review how one might directly compute an RSA signature, i.e. calculate c = md mod n. The standard approach is the “square-and-multiply” algorithm, which reads the binary representation of d bit by bit to compute md mod n. Here’s what it looks like in practice:
- Start with c = 1.
- Read out each bit of the exponent d, left to right:
- If the bit is 0, replace c with c2 mod n
- If the bit is 1, replace c with c2 * m mod n
To see why this works, take d = 17. In binary, d = 0b10001. Reading the bits of d left to right, our result becomes (dropping the “mod n” in each line for clarity)
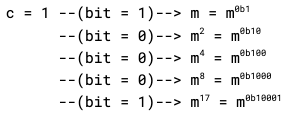
Every time we see a ‘0’, we square our result, which doubles the exponent, which in turn puts a binary ‘0’ on the end of the exponent. Every time we see a ‘1’, we square our result and multiply by m, which doubles and adds one to the exponent, putting a binary ‘1’ there instead. Bit by bit, we build out our exponent.
While this modular exponentiation (or “modexp”) algorithm is perfectly functional, its runtime scales by the cube of the bitlength of its inputs. As such, we’d rather make use of this modexp algorithm mod p and mod q, instead of mod n.
Here’s what a divide and conquer RSA with CRT approach might look like instead:
- [Divide] Compute mp = m mod p and mq = m mod q
- [Conquer] Calculate cp = (mp)d mod p and cq = (mq)d mod q (using square-and-multiply)
- [Reconstruct] Use cp and cq to recover the unique c where c mod p = cp and c mod q = cq
This will certainly speed things up, but we can do even better. Recall that by Fermat’s Little Theorem, any number raised to the power of (p-1) mod p is equivalent to 1 mod p. This means that, if we write d as d = (d mod (p - 1)) + k(p - 1) for some k, we can just cancel out the k(p - 1) when performing our modexp. This means we can rewrite the algorithm as
- …
- [Conquer] Calculate cp = (mp)d mod (p - 1) mod p and cq = (mq)d mod (q - 1) mod q
- …
which halves the time it takes to compute cp and cq with our square-and-multiply algorithm, since there are now half as many bits in our exponent.
To complete our RSA CRT algorithm, let’s think about how we’d actually implement each step. The first step, labeled “[Divide]” above, can be done using simple modular reduction: we can just perform long division and take the remainder. The ‘conquer’ step can be done using our square-and-multiply algorithm. What about the reconstruction step? The CRT guarantees us a unique c with c mod p = cp and c mod q = cq, but it doesn’t provide us an explicit way to recover that c.
Fortunately, there is an explicit formula we can use: Garner’s formula. Given cp and cq, we can recover c as
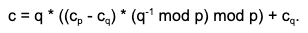
To see why this formula works, we manually compute
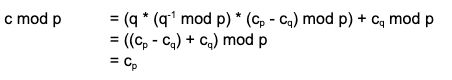
and

just as we hoped.
While most of this formula is addition and multiplication mod q, there is the need to compute q-1 mod p, which is a bit more expensive. Fortunately, this value doesn’t depend on our base or exponent, just the cofactors of n, so we can precompute it along with dp = d mod (p - 1) and dq = d mod (q - 1) when we generate our RSA keys.
At last, our complete version of the RSA CRT modexp algorithm is (changes in bold):
- [Preconditions] Assume we’ve already precomputed dp = d mod (p - 1), dq = d mod (q - 1), and qinv = q -1 mod p.
- [Divide] Compute mp = m mod p and mq = m mod q
- [Conquer] Calculate cp = (mp )^(dp) mod p and cq = (mq )^(dq) mod q, using the square-and-multiply algorithm
- [Reconstruct] Recover c = q * ((cp- cq ) * qinv mod p) + cq as the result
For a performance estimate, we note that the runtime in practice is dominated by the two modular exponentiations in the ‘conquer’ step. Since p and q are half the size of n, the two modexp calls together should take 2 * (1/2) 3 = 1/4 of the time of the direct approach, giving an upper bound of a 4x speedup. As the performance table at the top of this post shows, we can quickly approach this in practice for large RSA sizes where the exponentiations mod p and q dominate the runtime.
That’s all for this installment, but stay tuned for part 2 to hear how these mathematical changes transform the code itself!
If you’re interested in learning more about our approach to maintainable, production-grade cryptography, or hearing about ZeroRISC in general, sign up for our early-access program or reach out at info@zerorisc.com.
Tidying Up: FIPS-Compliant Secure Zeroization for OTP
This blog post covers ZeroRISC’s recent contributions implementing one-time programmable (OTP) memory zeroization to achieve FIPS 140-3 compliance. We did this in partnership with Rivos Inc, using the code at git hash 032df24, as part of our commitment to aligning open silicon with important industry security standards. A future post will describe how we’re advancing that mission further via the GlobalPlatform organization’s Trusted Open Silicon Task Force.
This blog post covers ZeroRISC’s recent contributions implementing one-time programmable (OTP) memory zeroization to achieve FIPS 140-3 compliance. We did this in partnership with Rivos Inc, using the code at git hash 032df24, as part of our commitment to aligning open silicon with important industry security standards. A future post will describe how we’re advancing that mission further via the GlobalPlatform organization’s Trusted Open Silicon Task Force.
In this technical post, we’ll address what the FIPS 140-3 requirements for zeroization are, how we improved the prior OTP design to meet these requirements, and what the hardware verification process looked like.
Zeroization and FIPS 140-3: Erasing Secrets Safely
There are many ways a secure device can reach its end of life, including planned decommissioning of a functioning device or return of a defective one. Regardless of context, it’s critical that no cryptographic secrets remain on a device once it’s taken out of service and changes hands.
The typical process for this is zeroization: at a device’s end of life, a special routine is run on the device to zero out all sensitive regions of OTP. In practice, this means blowing all the remaining OTP fuses, leaving the memory cleared.
While this may sound like a straightforward operation, there are a number of details that make zeroization tricky to implement:
Blowing fuses requires a lot of charge, so fuses need to be blown word-by-word
Due to manufacturing variations, a small fraction of OTP fuses may simply not blow
If power loss happens during zeroization, the device may be in an in-between state where some secrets are still accessible but others aren’t
The device must be able to reliably determine whether zeroization completed
As such, zeroization is a good target for standardization. FIPS 140-3 dictates a number of requirements regarding zeroization, summarized in the Implementation Guidance for FIPS 140-3 sections 9.7.A and B. At a high level, these state that zeroization…
…must overwrite all secrets with 0s, 1s, or random data (assertion AS09.30).
…must inform the device to treat zeroized values as inaccessible (assertion AS09.29).
…must erase any integrity values like checksums for secrets (assertion AS09.28).
…must somehow indicate a completion status to a user (assertion AS09.33).
It is important to note that FIPS 140-3 extends the prior zeroization requirements of critical security parameters (CSPs) to also include all unprotected sensitive security parameters (SSPs), regardless of their security level, along with public keys. To see what meeting these requirements looks like in practice, let’s review our approach to OTP zeroization.
Practical Zeroization: How to Tidy Up OTP
As a first practical detail, we need to consider which parts of OTP should be zeroized in the first place. In order to store different kinds of device state, the OTP is split up into partitions, some of which contain secrets that should be zeroized, and some of which contain data that shouldn’t.
One example is the lifecycle partition, which records whether a chip has been deployed or if it’s been returned to manufacturer. Since the chip relies on this partition’s data to determine what should be accessible, zeroizing this partition would render a chip unusable.
As such, we add a zeroizable control field to the memory map for the OTP partitions; by changing this flag, the hardware enforces whether or not the zeroization mechanism can clear that partition:

During generation of the OTP RTL, we check this field when generating partition offsets, allocating a 64-bit field after the digest indicating whether zeroization has happened. Each zeroizable OTP region then looks like

where the last 64 bits can be all set to 1 (a blown fuse) to indicate that the partition has been zeroized.
To address the possibility of “stuck at zero” fuses during zeroization, we use a dedicated integrator-tunable parameter for what fraction of bits correctly cleared indicates a proper zeroization. If the OTP controller detects say >90% of fuses blown in the zeroization marker, then it’s reasonable to consider the partition truly zeroized.
For triggering zeroization itself, the OTP’s existing Direct Access Interface (DAI) is used with the addition of a new command field. By setting the ZEROIZE bit in DIRECT_ACCESS_CMD register, the OTP controller will zeroize values at a provided address and then return the number of fuses which actually ended up blown. By sequentially clearing each zeroizable OTP field using this DAI interface, a dedicated zeroization application can clear all secrets from the chip without having to worry about manually tracking zeroization markers.
As a last detail, it may seem inconsequential whether we set the zeroization marker for a partition before clearing the partition or after, as by the end of zeroization the result is the same. It turns out that this ordering is actually important both to security and certifiability: by setting the marker before clearing the partition, we prevent power loss mid-zeroization from leaving partially-zeroized partitions marked as usable by the processor.
Checking our Work: Verifying our Zeroization Logic
By the time OTP zeroization happens, a device could be in any number of states. As part of implementing OTP zeroization, we need to be certain that whatever state the device is in before zeroization, it is both deterministically usable/non-usable per operator policy and properly zeroized afterward.
To do this, we took a pure Universal Verification Methodology (UVM) approach with constrained-random stimulus, targeted sequences, and comprehensive functional coverage. For a review of UVM, there are many excellent guides online including this one from ChipVerify.
How We Verified It: A Config-Aware UVM DV Strategy
The aim of this effort was two-fold: to ensure that zeroization works regardless of state, and that even under adverse conditions, the OTP is left in a functioning state. As such, two key virtual sequences were introduced:
otp_ctrl_zeroization_vseq.sv, which triggers zeroization under stress (DAI, CSR access)
otp_ctrl_zeroization_with_checks_vseq.sv, which adds post-zeroization integrity and access checks
To ensure coverage across various chip states, these sequences randomly select:
Target OTP partition (vendor, creator, etc.)
Partition offset (start, middle, digest, or zeroization trigger address)
Whether the partition is zeroizable or not
Additionally, the scoreboard and monitor were enhanced to
Track pre-zeroization state per partition
Verify post-zeroization expected values (zeroized -> all 1s, non-zeroized -> unchanged)
Detect illegal reads from secret partitions (even if data is zeroized)
Using these changes, we can ensure that the OTP zeroization mechanism has been tested for every possible combination of factors that it could encounter in the real world.
Functional Coverage: Closing the Loop
To ensure coverage, we added two config-aware covergroups to ensure 100% scenario closure.
The first is zr_dai_cmd_cg, which handles zeroization DAI command coverage. This covergroup samples every DAI access during and after zeroization with the following dimensions:

The second, complementary covergroup is zr_partition_read_cg, which handles post-zeroization read behavior by cross-covering five dimensions for each partition:

Config-Driven DV: One Testbench, Any OTP Layout
In order to make this testing framework maintainable, it needs to adapt to any changes to the OTP layout. As such, we made the testbench configuration-driven: any changes to the OTP memory map are reflected in the virtual sequences, scoreboard, and covergroups. Upon building the testbench, the HJSON OTP memory map is parsed and the resulting partitions are used to fill in Mako templates for the testbench source files:

Using this approach, the test bench is able to immediately adapt to updates to the OTP memory map, ensuring that what’s tested is exactly in sync with what will be taped out.
Result: Provable Zeroization
Together, these elements of our testbench allow us to continuously ensure that the OTP zeroization mechanism works exactly as intended. Below is a table of the properties we were able to verify regarding this mechanism:

Because of the configuration-driven design of the test bench, we are able to continuously verify these properties for any integration of the OTP controller.
Conclusion
When working with secure systems, conceptually simple tasks such as OTP zeroization can require a remarkable degree of care and effort to incorporate properly. Practical security considerations, standards compliance, and maintainability all need to play a part in engineering design choices, and rigorous digital verification is essential.
If you’re interested in learning more about ZeroRISC and our open silicon approach to device integrity, drop us a note at info@zerorisc.com.
Bridging Hardware and Software: Summer Interns Making an Impact at ZeroRISC
This blog post is the second in our two-part summer internship series. Following Beshr’s great work on porting Enabling Position-Independent Code and Dynamic Memory Management in ZeroRISC OS, Yeabsira tackled porting OpenTitan’s interconnect from TL-UL to AXI.
This blog post is the second in our two-part summer internship series. Following Beshr’s great work on porting Enabling Position-Independent Code and Dynamic Memory Management in ZeroRISC OS, Yeabsira tackled porting OpenTitan’s interconnect from TL-UL to AXI.
Introduction
Yeabsira is a rising senior at MIT studying Electrical Engineering & Computer Science, with a passion for the hardware stack - from digital systems and chip design to all things low-level. When not engineering, he can be found kickboxing, laying down jazz grooves on his bass guitar, or tinkering with audio circuits.
Extending OpenTitan to AXI
My project focused on porting OpenTitan to AXI. OpenTitan’s interconnect is currently TL-UL (TileLink Uncached Light-Weight), which works well. However, many common IP blocks, debug probes, and FPGA tools use AXI. Generating AXI-compatible IP allows straightforward integration with AXI-enabled designs and leverages existing AXI-based DV collateral to enhance verification. My goal was to start an incremental conversion to AXI, beginning with AXI-based register interface transactions while preserving the TL-UL interconnect.
I developed two key RTL components.
The first is a TL-UL to AXI bridge, which repackages TL-UL host-to-device (H2D) requests into AXI and AXI’s device-to-host (D2H) responses back into TL-UL D2H responses.
The second is the AXI AdapterReg, replicating TL-UL AdapterReg functionality. This module translates TL-UL H2D requests into peripheral CSR read/write operations and returns results as TL-UL D2H responses, providing a clean communication path. The AXI AdapterReg maintains the CSR handshake while exposing an AXI D2H interface upstream, allowing AXI hosts to communicate directly with peripherals. By replacing TL-UL AdapterReg with the bridge + AXI AdapterReg, full DV regression can be rerun, supporting functional equivalence and incremental migration to AXI-native IP.
The simplified diagram below illustrates the implementation and how a fully AXI-enabled open silicon blocks could function in the future.
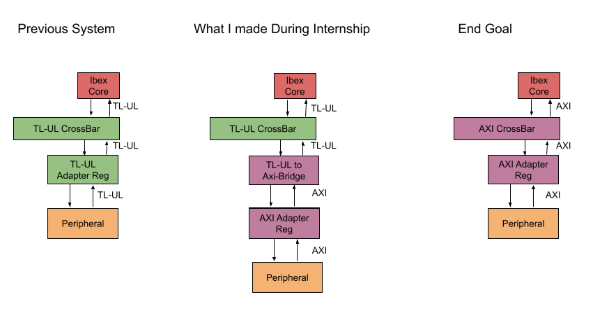
The Bridge
Understanding the bridge requires comparing TL-UL and AXI. TL-UL has two channels: A_Channel for requests and D_Channel for responses. Signals are shared between reads and writes, with A_Opcode indicating request type. OpenTitan-derived IP adds user bits for response integrity.
AXI uses five separate channels: AW (write addresses), W (write data), AR (read addresses), R (read responses), and B (write responses). Each has its own handshake, so signals are not shared between reads and writes.
I implemented flip-flop registers to capture TL-UL input signals during handshakes. Based on A_Opcode, requests are mapped to the appropriate AXI channels. AXI D2H responses are then routed back to TL-UL D2H outputs according to the registered request type.
A notable challenge involved handling AW and W handshakes, which can occur independently. The solution was a state machine tracking AW and W, waiting for the other handshake when only one occurs. Currently, the bridge supports a single inflight request at a time, ensuring clear and reliable state transitions. The diagram and accompanying state machine illustrate the timing and toggling of each signal.
AXI AdapterReg
The AXI AdapterReg sits in front of each peripheral, translating AXI transactions into CSR accesses and returning AXI responses. It can also be integrated into the current TL-UL-based system via the bridge.
Its scope is narrower than the bridge, converting AXI’s split channels into a single CSR-side handshake. The CSR interface asserts we_o for writes, re_o for reads, passes address, data, and byte enables, and expects rdata_i or error_i. Only one inflight request is supported, so responses are immediately matched, and AXI ready signals remain low until completion.
Error handling was a critical focus. Differences between TL-UL and AXI can introduce cycle delays or missed errors. The AdapterReg and bridge communicate via an error_i/error_o handshake to ensure detected errors propagate correctly and prevent unhandled system failures.
Testing
Approximately 30% of my effort went into RTL design, and 70% into testing and debugging. Iterative simulation is crucial, as FPGA iteration is slow. I validated the design first in Verilator, then on FPGA, and finally in the full-chip environment, resolving major issues beforehand.
Tests revealed response integrity mismatches, cycle delays in error propagation, address alignment issues, AXI handshake quirks, and the need for the AW/W state machine. Each failed test guided design improvements, producing a robust bridge and AdapterReg ready for full-chip integration.
Impact and Benefits
My bridge and AXI AdapterReg now pass top-level DV regression and are being prepared for PR to main. Enabling AXI support allows for easier integration into more commercial silicon. Future work includes an AXI Host AdapterReg, enabling common open source RISC-V cores like Ibex to communicate with an AXI interconnect.
Beyond technical skills, I gained experience designing a system from scratch, integrating it into a larger chip, debugging complex issues, and understanding UVM-driven verification workflows. Collaboration with full-time engineers accelerated learning and allowed project completion, highlighting the value of curiosity, persistence, and hands-on problem-solving in digital systems engineering.
My experience demonstrates how early involvement in substantial RTL projects at ZeroRISC provides exposure to real-world digital systems challenges, making it an ideal environment for aspiring engineers seeking meaningful and technically rich work.
Conclusion
Yeabsira’s time at ZeroRISC shows how internships offer meaningful, hands-on exposure to real-world digital systems challenges. From designing and testing complex RTL components to understanding verification flows and system-level integration, interns leave with practical skills and insights that are hard to gain elsewhere. Stay tuned for future updates on our AXI work, and an announcement of its full open source release.
We’re proud of our interns' contributions and grateful for the fresh ideas and energy they brought to ZeroRISC this past summer. Their work not only advances our projects but also demonstrates the kind of learning, growth, and impact our internship program offers.
If you’re interested in learning more about our internship program or exploring collaboration opportunities with ZeroRISC, please visit our Career page.
ZeroRISC’s Summer Interns Expand Runtime Flexibility of our SecureOS
This Summer, ZeroRISC had the pleasure of hosting two Summer interns in our Boston office. This blog post is the first in a two-part series highlighting their work tackling challenging real-world problems at the intersection of hardware and software.
This Summer, ZeroRISC had the pleasure of hosting two Summer interns in our Boston office. This blog post is the first in a two-part series highlighting their work tackling challenging real-world problems at the intersection of hardware and software.
Beshr Bouli, this post's primary author, is a rising junior at MIT majoring in Computer Science and Mathematics. He’s interested in both low-level systems like OS’s and compilers and large-scale systems like distributed networks. He’s a dedicated competitive programmer outside the classroom and an avid soccer enthusiast who plays, watches, and organizes the game with equal passion.
His project focused on enabling Position-Independent Code (PIC) and implementing dynamic memory management in ZeroRISC’s Rust-based secure operating system, built on top of TockOS, allowing multi-application execution on MMU-less systems with greater runtime flexibility and improved memory efficiency.
The following is Beshr’s report on his Summer internship with us.
Enabling Position-Independent Code and Dynamic Memory Management
As part of our full-stack philosophy, ZeroRISC supports a Rust-based embedded OS co-developed atop OpenTitan hardware – extending hardware security guarantees into the software. A key feature of this OS is its ability to load and run multiple applications simultaneously. Since OpenTitan does not provide a Memory Management Unit (MMU), the OS cannot assign a virtual address space to each process. While this is not a security concern due to the use of a Memory Protection Unit (MPU), it forces all processes to share the same address space. My internship this Summer focused on increasing flexibility around this memory bottleneck by integrating Position-Independent Code (PIC) and making other core OS enhancements.
Below is a simplified system overview showing all the components my project involved:

Position-Independent Code (PIC)
Compilers typically generate code assuming exclusive control over memory, placing code and data at fixed addresses. On MMU-based systems, the MMU handles virtual-to-physical address translation, but MMU-less systems must handle memory differently. Previously, applications were assigned fixed addresses at compile time, for example, Application A at 0x21000 and Application B at 0x22000. This static allocation leads to memory inefficiency, fragmentation, and difficulty accommodating applications that grow or are unknown at compile time.
I implemented a comprehensive pipeline from compiler to loader, producing binaries that do not assume specific RAM addresses. The focus was on making C applications built with the Clang LLVM-based toolchain position-independent.
Compiler
In my pipeline, the compiler now generates assembly that uses program counter (PC)-relative addressing for code instead of absolute addresses. Note that the PIC memory accesses remain valid regardless of where the binary is loaded, because they are relative rather than absolute. For example:

However, this isn’t the complete solution. Binaries consist of two independently relocatable segments: the code segment, which is backed by read-only memory, and the data segment, which is read-write and located on SRAM. PC-relative addressing works for code segments stored in read-only Flash, but the data segment is loaded dynamically into SRAM, so its addresses are unknown at compile time. This is solved using global pointer (GP)-relative addressing, allowing data to be accessed relative to the GP, which is set at load time. For example:

Other ELF segments are mapped to PIC segments based on read/write permissions, with constants typically in the code segment and .bss in the data segment.
Linker
The linker finalizes the locations of objects whose placement is unknown at compile time. For example, in C code with externally defined constants, the linker rewrites the compiler’s pseudoinstructions to ensure that the correct relocation sequences are applied depending on whether objects reside in read-only or writable memory.
Loader and Final Relocation
Now that we have assembly code that doesn’t make assumptions about addresses, we need to appropriately set up the environment for the assembly code to run in. Specifically, I modified the C runtime (crt0) to perform runtime initialization and relocation. Code segments remain in Flash, while data segments are loaded into SRAM. The loader sets GP after loading the data segment and finalizes relocation for variables requiring absolute addresses, including constant pointers that are mapped into SRAM to allow updates. Finally, the PC is set to the application entry point, achieving fully position-independent execution.

Memory Management
With PIC implemented, memory can now be managed more flexibly. Previously, applications had fixed memory requirements, which limited dynamic allocation and overall system efficiency. Beshr designed a variable-size-block memory allocator to optimize usage.
Each memory block contains a header with size and allocation status, forming a linked list. For PIC allocations, the allocator uses a best-fit strategy; for non-PIC allocations, it checks that the requested address and size fit within a free block. Blocks can be split to minimize wasted memory, and deallocation coalesces adjacent free blocks.

More complex allocation methods such as segregated lists were considered but rejected, as they would increase OS size and thus decrease memory efficiency. The chosen design balances simplicity, memory conservation, and fragmentation reduction.
Impact and Benefits
The combination of PIC and the new memory allocator enables dynamic loading, updating, and unloading of applications at runtime, without recompilation or manual memory management. Previously, memory had to be statically divided among applications, leaving little flexibility for runtime changes.
Now, the OS loader can manage application placement dynamically, optimize memory usage, and reduce downtime, significantly improving system flexibility and efficiency. These changes provide a new level of abstraction, allowing developers and users to deploy applications without concern for SRAM addresses or memory fragmentation.
I had a great Summer at ZeroRISC and look forward to diving more deeply into OS in the future!
Conclusion
It was our privilege to host Beshr and we’re grateful for all his outstanding work this Summer!
Beshr’s project demonstrates how system-level software engineering and compiler/runtime integration can enhance MMU-less embedded systems, providing both efficiency and flexibility for secure, multi-application execution.
At ZeroRISC, we believe strongly in the power of open source to fuel innovation and amortize maintenance effort over the long term. So, we are currently coordinating with the Tock team on integrating Beshr’s PIC efforts into the relevant upstream Tock repositories.
While Beshr explored enhancements to ZeroRISC’s Rust-based secure operating system, including position-independent code (PIC) and a flexible memory allocator, our second intern, Yeabsira, focused on hardware and interconnects. Look out for that blog coming out shortly!
ZeroRISC and Tock OS Team Present Tutorial at ACM MobiSys 2025
On July 4th, ZeroRISC and the Tock secure embedded OS development team jointly presented a full-day tutorial on secure firmware design for hardware roots of trust (HWRoTs) using Tock.
This tutorial spotlighted Tock's memory protection, process management, and compiler-derived kernel isolation guarantees, providing a comprehensive view of how Tock can uphold HWRoT security requirements from userspace down to the metal.
On July 4th, ZeroRISC and the Tock secure embedded OS development team jointly presented a full-day tutorial on secure firmware design for hardware roots of trust (HWRoTs) using Tock.
This tutorial spotlighted Tock's memory protection, process management, and compiler-derived kernel isolation guarantees, providing a comprehensive view of how Tock can uphold HWRoT security requirements from userspace down to the metal.
As the primary author of the HWRoT-specific section of the tutorial, I deeply enjoyed the process of preparing and delivering the relevant materials. To make it useful as an onramp for others to learn more about Tock and general hardware security, I’ve put this post together.
We will review what Tock is and why its design is powerful for trusted hardware development, concluding with the highlights of the tutorial we shared. Please review the tutorial available here as part of the Tock Book for a more advanced overview. Following along at home only requires a development board and OLED screen breakout; see the Hardware Setup page in the Tock Book for details.
What is Tock?
Tock OS is a Rust-based embedded operating system designed for securely running multiple untrusted applications at once with strong isolation guarantees. By carefully leveraging embedded memory protection hardware and guarantees provided by Rust’s type system, Tock manages to offer both runtime isolation guarantees for applications, and compile-time isolation guarantees between different parts of the kernel, all while allowing applications to be both loaded on demand and completely untrusted.
Delving into runtime isolation, nearly all embedded devices have some support for hardware memory protection. Two common examples of such mechanisms are ARM’s Memory Protection Unit (MPU) specifications and RISC-V’s Physical Memory Protection (PMP).
Such mechanisms work by providing a hardware block in the processor with a fixed number of “slots” representing spans of physical memory. Each slot generally has associated permissions, such as:
RW (read-write) for a region of SRAM
RX (read-execute) for a flash region holding application code
RWX (read-write-execute) for a RISC-V Debug Module debug region
These can all be modified via memory-mapped registers. Memory addresses not in any provided region are generally treated as inaccessible. To enforce such a set of permissioned regions, these mechanisms monitor all processor memory accesses and fault the processor whenever the access policy given by these regions is violated.
Diagram illustrating a RISC-V PMP configuration. Each PMP region is a contiguous range of memory addresses which can be configured as readable, writable, and/or executable. If a memory access by the processor falls outside of the policy set by these regions, the processor will fault.
Tock’s context switching code carefully makes use of the memory protection mechanisms in several different processor architectures, limiting applications to exactly the memory they should access without assuming anything about how the application binary was constructed.
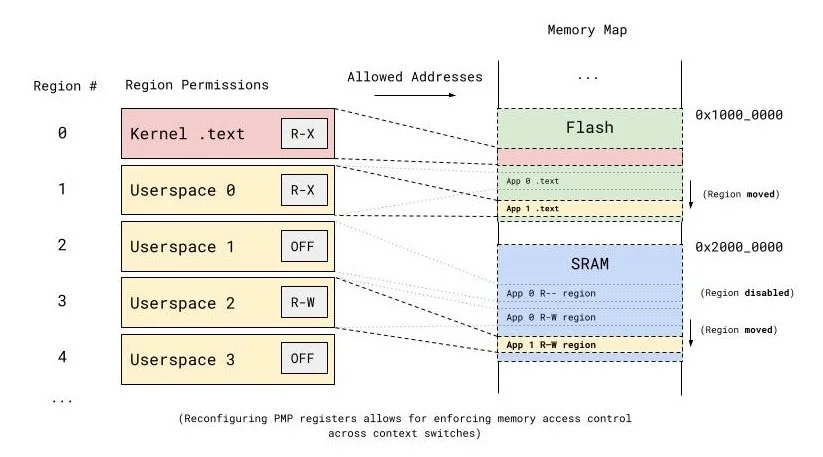
Diagram illustrating how the RISC-V PMP configuration is reconfigured on context switch. Since a different process's .text section and allowed SRAM regions will be used, PMP regions need to be shifted and even added/removed correspondingly.
In contrast, Tock’s kernel is designed such that isolation between components of the kernel, called capsules, is given at compile-time. In particular, Tock capsules can only be written using safe Rust, a subset of the Rust language that provides strong type-safety and memory-safety guarantees. In particular, safe Rust disallows constructing references to arbitrary memory, preventing capsules from accessing each other’s data except when explicitly permitted.
Moreover, Tock leverages this fact in several completely novel measures to prevent capsules from faulting the kernel as a whole. One key example is memory grants: rather than use a kernel heap that one capsule could exhaust, applications instead grant access to small portions of their memory via the syscall interface to provide heap space for capsules.

Diagram illustrating Tock's core architecture. Rather than maintain a global heap, Tock allocates an associated "grant" region for each application. This is memory which can be delegated piecemeal by the application to parts of the kernel as heap space, preventing a single kernel component from exhausting the heap for the whole system. (https://tockos.org/assets/img/architecture.png with permission)
In this manner, the portion of a Tock-based SoC that needs to be fully trusted remains quite minimal relative to other embedded OSes. For more details, the Tock website’s Design page is an excellent overview.
What makes a Hardware Platform Secure?
A secure hardware platform is often a subsystem of a larger device that provides some level of cryptographically-enforced trust to a larger system. For instance, a hardware root of trust (HWRoT) is a secure hardware platform responsible for the following:
Securely store cryptographic keys on behalf of the system it belongs to
Allow other subsystems to delegate cryptographic operations
Perform secure boot for the full system
Attest to the present firmware and configuration of the system
Encrypt and decrypting secure storage mediums
Coordinate device firmware updates for the full system
While a general-purpose processor could feasibly perform all of these operations; the key with a secure hardware platform is that these operations are performed in a dedicated, extensively-tested, and hardened subsystem, which can withstand attacks that a general-purpose processor will not.
Depending on the security and standardization requirements of a device, a secure hardware platform might be required to complete the following:
Prevent side-channel attacks by making use of constant-time, masked hardware implementations of cryptographic operations
Resist fault-injection attacks with a hardened processor design and fault detection logic
Detect active tampering using dedicated analog sensors and zeroize data in response
Leverage hardware-backed key stores to prevent direct key exfiltration by firmware
Undergo extensive third-party security review and even formal analysis to provide strong security guarantees
The aim is for other subsystems to be able to confidently rely on the platform’s integrity and confidentiality guarantees, delegating management of sensitive data and operations instead of undergoing the same degree of hardening.
Some notable secure hardware platforms in the wild include:
The general-purpose, open-access OpenTitan Silicon RoT, which comes in both discrete and integrated flavors
Apple's Secure Enclave, the integrated root of trust in iPhone mobile processors
Hewlett Packard Enterprise's Silicon Root of Trust, the integrated root of trust in their out-of-band management chip
Infineon's SLE78 Secure Element, which is used in YubiKey 5 series USB security keys
While these platforms are physical hardware systems, they all rely on firmware in order to make precise, careful use of the secure hardware. Two critical points to note are:
Secure firmware without secure hardware leaves the system open to a variety of hardware attacks, like side-channel analysis and fault injection attacks.
Secure hardware without secure firmware is vulnerable to the same set of firmware-level attacks that a general-purpose processor might be.
As such, a secure hardware platform must be realized as a joint, even co-designed system carefully assembled with the complementary security guarantees of hardware and software in mind. Firmware can make or break the security guarantees of a hardware platform; as such, careful consideration of what embedded OS the system leverages is due.
Why Tock as an OS for Secure Hardware?
As previously illustrated, Tock provides excellent security and isolation guarantees by design while allowing untrusted multi-tenancy, critical for delivering the various complex services a secure hardware platform must provide to its surrounding system.
Moreover, its careful design around the Rust language allows for the elimination of broad classes of memory and type safety violations at compile-time, critical for the delivery of truly secure systems in timeframes appropriate to a fast-moving market.
Yet, Tock serves as an excellent secure hardware platform OS for a more innate reason. Secure hardware isn’t designed as a monolith; typically, a well-designed secure hardware platform will be split into several stages which boot in sequence. In a secure hardware platform like a HWRoT, these form a chain of trust, inductively ensuring the security of the whole system. For example, when performing secure boot:
Boot stage 0 will be immutable (usually as mask ROM)
Boot stage n + 1 will be verified to match a manufacturer-signed hash by boot stage n before handing over control flow
Similarly, for attestation:
Boot stage 0 will be immutable (usually as mask ROM)
Boot stage n will generate a signature of boot stage n + 1’s hash, then lock write access to the certificate for later boot layers
The hierarchical nature of these dual processes allows for reasoning about a small part of the system at a time, allowing for both modularity and a granular permissioning structure. For instance, in a secure microprocessor the boot stages might take the form of

This is where each stage verifies and attests to the state of the next, and
ROM (the mask ROM) is baked into mask ROM
ROM_EXT (ROM extension) lies in flash, and is signed by the chip’s creator for security updates
BL (the bootloader) lies in flash, and is signed by the chip’s owner for everyday firmware updates
Tock’s design and trust model allows for seamlessly extending this chain of trust, instantiating the bootloader with Tock’s boot code and using applications as later boot stages. Because Tock has built-in support for application code signing and can be securely extended to provide application attestation, we can make our chain of trust become

As Tock provides strong compile-time isolation between kernel components, the application verification and attestation components of Tock can be carefully verified and isolated. Similarly, Tock’s design allowing for untrusted, hot-loadable, code-signed applications means that application code signing permissions can be trivially delegated to and revoked from a third-party by the device owner on demand.
Moreover, the kernel components that each application relies on–for instance, a secure signing service might rely on a hardware ECDSA driver–can be easily isolated and verified individually, providing defense in depth within the kernel even when a singular driver might be compromised.
In summary, this makes Tock a viable option for providing a reliable, secure, extensible OS for secure system design.
New Tock Book Section: Tock as a Root of Trust OS
As part of delivering our demo at MobiSys, zeroRISC and Tock OS developers contributed a chapter to the Tock OS Book, Tock as a Hardware Root of Trust Operating System.
This chapter, available here, focuses on building a toy encryption service as a Tock application to mimic the behavior of a small HWRoT like a secure element. From there, the reader is guided through a set of increasingly invasive attacks on the system, highlighting Tock's ability to provide defense in depth in practical applications as highlighted above.
I recommend reviewing this tutorial, and encourage readers to share feedback with us. If you’re interested in learning more, please take a look at our early-access program or contact us at info@zerorisc.com.
Conclusion
Secure hardware platforms are modern examples of where careful simultaneous consideration of hardware and software together is critical to success.
Tock, a modern Rust-based embedded OS, is an excellent example of how an operating system can complement the security guarantees of the hardware it runs on in a seamless fashion. At zeroRISC, we care about delivering strong security guarantees that extend up to the application software our customers rely on, and leveraging modern, secure embedded OS design is a critical part of being able to deliver that in practice.
Future of PQC on OpenTitan
This is part 3 of 3 in an experience report about implementing SPHINCS+ (aka SLH-DSA) for secure boot in OpenTitan root of trust (RoT) chips. SPHINCS+ is a post-quantum secure signature algorithm and one of the four winners of NIST’s post-quantum cryptography competition; the final standard was recently released as FIPS 205.
This is part 3 of 3 in an experience report about implementing SPHINCS+ (aka SLH-DSA) for secure boot in OpenTitan root of trust (RoT) chips (1,2). SPHINCS+ is a post-quantum secure signature algorithm and one of the four winners of NIST’s post-quantum cryptography competition; the final standard was recently released as FIPS 205.
Read part 1 here and part 2 here.
This post will focus on the future of post-quantum cryptography on OpenTitan, specifically:
new SPHINCS+ parameter sets that dramatically improve secure boot tradeoffs, and
potential hardware modifications to support lattice-based cryptography on OpenTitan.
I said the last post would be the longest, but it looks like this one is. Turns out there’s a lot to say about the future!
New SPHINCS+ Parameter Sets
For the OpenTitan Earl Grey chip design, we set up the SPHINCS+ verification so that it’s a configuration option during manufacturing; you can decide to run secure boot using both classical non-PQC verification or using both classical and SPHINCS+. We continued to support the classical-only option because SPHINCS+, although fast enough to be tolerable, was still a few times slower than RSA or ECDSA. Specifically, SPHINCS+ with the shake-sha2-128s parameter set takes about 9.3ms on Earl Grey when clocked at 100MHz, compared to about 2.4ms for RSA-3072 and 4.2ms for ECDSA-P256, which provide about the same level of security.
This performance picture is about to change. The paper A note on SPHINCS+ parameter sets (2022), authored by Stefan Kölbl (one of the SPHINCS+ authors) and myself, explores new parameter sets that are better suited to firmware signing. As I described in the first post of this series, SPHINCS+ is a signature framework; it has several settings that you can tweak to get different characteristics. The NIST PQC competition required that all submissions support up to 2^64 signatures per key. This is so many signatures that, practically speaking, one can simply never worry about counting. For many applications, this is a pragmatic choice to reduce complexity and risk, especially when the same key may be used by multiple entities. For firmware signing specifically, the context is different; the signing environment is tightly controlled, and signing generally won’t happen more frequently than once per month in practice. In this context, 2^20 signatures are more than enough; that’s enough to sign once per month for 87,000 years, or once per day for 2,872 years. Even 2^10 signatures is enough to sign once per month for 85 years.
And if you exceed the number of signatures needed for the target security level, the characteristics of SPHINCS+ are such that the security level drops off very gradually; you would retain practical security, over 100 bits, even after signing over 1000x more than you should. This is a strong contrast with the LMS/XMSS signature schemes, where practical security is immediately lost if the state is mishandled even once.
So the question was: if the maximum number of signatures was relaxed, what new possibilities would that open up in the tradeoff space for SPHINCS+ parameters? Stefan built a way to automatically search through the parameter space (on GitHub: kste/spx-few/), and was able to map the landscape with detailed graphs like this one:

This was a promising result; targeting the same security value but a lower maximum number of signatures, it was possible to significantly reduce signature size without performance sacrifices. Optimizing for verification performance (since these parameter sets by definition target contexts where signing is infrequent) and signature size, the paper proposes effectively six new parameter sets, one each for the “s” variants in FIPS 205. The new parameters are called “Q20” in reference to the 2^20 signature bound, so the analogue of shake-128s from FIPS 205 is shake-128s-q20. The other signature framework parameters don’t change when the hash function changes, so sha2-128s-q20 is exactly the same as shake-128s-q20 except for the hash function.
OpenTitan was the case study for firmware signing in the paper, due to its combination of production quality implementation and open-source availability. I ran benchmarks for several of the new parameter sets using our secure boot implementation. For shake-128s-q20, which is the security level we’d most likely target, we saw a whopping 58% decrease in signature size and a 79% reduction in verification time.

The branch with the benchmarking scripts and reproduction instructions is available at jadephilipoom/opentitan:spx-benchmark
That speedup is enough to make SPHINCS+ as fast or faster than classical, non-post-quantum cryptography. On OpenTitan, that’s nearly as fast as RSA, and significantly faster than ECDSA at the same security level (note that the ECDSA number is slightly outdated, it’s now more like 420K cycles; we’ve made some speed improvements since the paper benchmarks were measured).

Although the signature size is still larger, it’s now only 4x larger than RSA’s combined public key and signature size (as discussed in the first post, it’s the sum of the two that really matters). The existing FIPS 205 parameter set is nearly 10x larger. This is a huge improvement to the tradeoff space of working with SPHINCS+ for firmware signing.
Now that we have an implementation for SHA-2 parameters rather than SHAKE, I can add some new benchmarks, shown here for the first time:

As discussed in the previous post, the SHA-2 parameters are faster on OpenTitan because the SHA-2 accelerator hardware implementation has less power side-channel hardening than the SHAKE accelerator. For secure boot, where we only do verification and therefore never handle secret data, we don’t need the hardening, so the speed is a free advantage. With SHA-2 and the Q20 parameters, SPHINCS+ is in fact significantly faster than RSA, and more than twice as fast as ECDSA, making it a very practical choice for the boot process despite the large signatures.
We’re very enthusiastic about these new parameter sets, which were presented at the 5th NIST PQC Standardization Conference in April 2024. At the same conference, NIST announced that they indeed plan to standardize some parameter sets for smaller numbers of signatures, in a separate publication from FIPS 205. We strongly support the standardization of reduced-maximum-signature parameter sets. Standardizing them will help hardware projects like ours roll out PQC quickly and effectively, a necessary precondition for the PQC migration of any system that relies on secure boot.
Hardware Acceleration for Lattice Cryptography
Hardware security means more than just secure boot. In some cases, we might want to be able to run alternative post-quantum signature algorithms on OpenTitan, especially for cases where we need to compute a signature (rather than only verify one). Signing speed, for example, is not a strength of SPHINCS+. Also, some of the data we handle in signing and key generation is secret, so side-channel attacks (e.g. power and timing) are in scope. Defending against these side channels is probably well within reason if we use the SHAKE parameter set, since that has a masked hardware implementation.
Another concern for signing is fault injection, and this one is trickier for SPHINCS+. I touched on these in the last post; it means that the attacker uses a laser or other means to deliberately insert a glitch during computation. The 2018 paper Grafting Trees: a Fault Attack against the SPHINCS framework described an attack that essentially causes SPHINCS+ (and several other related schemes) to reuse an internal one-time signature. The resulting faulty signatures pass verification, but reveal information to the attacker that, with enough signatures, allows them to create forgeries. The attack was experimentally verified shortly after being published, and a recent analysis confirms that the only real defense is redundancy. In other words, we would have to perform each signature twice or more to protect against this scenario. Given that signing is already pretty slow, this isn’t ideal for something we might have to do relatively frequently. It’s still viable to do SPHINCS+ signing and key generation on OpenTitan, and I believe we should support it. However, it would be good to support alternative post-quantum signatures as well.
Dilithium or Falcon?
So, what are the other options? Besides SPHINCS+, the other two signature algorithms that won the NIST competition are Dilithium (aka ML-DSA) and Falcon (aka FN-DSA). Here are some relevant benchmarks for ARM Cortex-M4, courtesy once again of the excellent pqm4 project. I’ve highlighted some particular measurements that are likely to be either challenging (yellow) or near-impossible (red) to accommodate during boot for an embedded system like OpenTitan with limited memory:

* Can also be stored as a 32-byte seed.
** Falcon signing is many times slower than this without floating-point instructions (this excellent and informative blog post from Bas Westerbaan at Cloudflare estimates about 20x slower).
As discussed in the first post of this series, I am using parameter sets here that aim for a higher security level than for SPHINCS+. This is a hedge against future cryptanalytic attacks potentially weakening lattice signature schemes, since they are newer and less well-understood than hash-based cryptography.
A few observations we can make based on the pqm4 measurements:
Dilithium signatures are almost 3x larger than Falcon ones.
Falcon key generation and signing are many times slower than Dilithium, especially taking into account that the current OpenTitan designs do not have floating point instructions.
The stack size required by the “clean” implementations is probably not feasible for an embedded system; we will need to use stack-optimized versions, and pay the price in code size and Dilithium signing speed.
Falcon code size is much larger than Dilithium.
We can likely accelerate Dilithium more than Falcon, because a much higher percentage of its computation is SHAKE hash computations that can use our hardware SHAKE accelerator.
Taking all of this information together, it’s clear that Dilithium is a more appealing option than Falcon for OpenTitan, at least with the current design. The code size alone for stack-optimized Falcon is probably disqualifying; that’s more SRAM than the current Earl Grey OpenTitan chip has. Besides that, the key generation and signing times are quite slow, even if we took the big step of adding floating-point instructions, and accelerating hashing won’t get us very far in speeding it up.
Another advantage of Dilithium is that the secret keys are derived from short seeds. This opens up the possibility to generate the secret keys from OpenTitan’s hardware key manager block. The key manager block maintains a secret internal state and performs key-derivation operations to generate key material that it loads directly into hardware blocks, for example the OTBN coprocessor that we currently use to accelerate ECDSA and RSA operations.
What about Kyber?
The fourth algorithm selected in the NIST PQC competition is Kyber, aka ML-KEM. Kyber is not a signature algorithm; instead, it is for “key encapsulation” and allows two parties to exchange information such that they end up with a shared symmetric key. This is an extremely useful operation; for example, TLS uses an exchange like this to set up an encrypted connection between a website’s server and a user’s browser. Once you do the key exchange operation, you can use fast “symmetric” cryptography like AES to encrypt data. Symmetric cryptography is post-quantum secure already, so there’s no need to change much here or accept performance penalties.
Although we don’t need Kyber at the moment for any of OpenTitan’s core device functions, it’s an algorithm that we expect high demand for, and it would be good to have a hardware architecture that supports it. Luckily, many of the underlying structures of Kyber are very similar to Dilithium, so we can consider them together.
The Design Space
So the next question is, how easily can OpenTitan (or, more precisely, a future hardware instantiation of OpenTitan) support efficient Dilithium and Kyber operations, and what challenges will we face there?
For the answers we can look to a pair of recent papers: Enabling Lattice-Based Post-Quantum Cryptography on the OpenTitan Platform (2023) and Towards ML-KEM & ML-DSA on OpenTitan (2024, pre-print – for full disclosure, I’m one of the authors). The first paper evaluates a more hardware-focused approach to supporting lattice cryptography, extending the OTBN coprocessor with a new post-quantum ALU and specialized instructions (3). It focuses on verification operations. The second paper evaluates four different hardware and software implementations of Dilithium and Kyber with OpenTitan’s OTBN coprocessor:
Unmodified OTBN ISA and hardware design, but without OTBN’s current memory constraints
Same as (1), but with a direct connection between OTBN and KMAC hardware blocks
Same as (2), but with the OTBN ISA extended with five new vector instructions
Same as (3), but with the hardware implementation of the new instructions optimized for speed instead of area.
Side channel defenses are also not in scope for either of the other papers, and will probably incur a significant cost in terms of code size, stack usage, and runtime. Luckily, the KMAC hardware block already includes these defenses, so the cost would only apply to the non-hashing computations. Although it’s difficult to estimate the exact cost of side channel countermeasures, it’s important to keep this in mind and leave a little bit of slack in the stats to accommodate the cost of side channel defense.
Memory optimizations would be necessary for our embedded context, and are not completely in scope for the above papers. However, from Dilithium for Memory Constrained Devices (2022) and the pqm4 measurements we can get a decent idea of the amount of slowdown we would have from stack optimizations, and how much we could bring stack usage down. This paper also helpfully optimizes for code size, supporting all 3 Dilithium variants in around 10kB of code.
Together, this research helps us get a sense of the tradeoff space available, primarily between hardware area, stack usage, and speed. Much thanks to all of the researchers involved; it’s amazing to be able to reference all of this information instead of guessing! This is also a great example of how an open source hardware project can benefit from external researchers having the ability to experiment.
So let’s dive in and see what these papers tell us, paying special attention to the three key tradeoffs of area, stack usage, and speed. Starting chronologically with Dilithium for Memory Constrained Devices, we can see that Dilithium-3 (ML-DSA-65) can be brought down from 50-80kB of memory usage for all operations to about 6.5kB for signing and key generation and 2.7kB for verification:

It’s important to remember here that the keys and signatures themselves often also need to exist in memory during the computation, and for lattice cryptography these are measured in kilobytes. On Earl Grey, OTBN has only 4kB of data memory, so this would clearly need to be a little bigger.
The cost for using less memory is performance; compared to a similarly generic and C-based implementation, PQClean, the slowdown is 1.5x for key generation, 2.8x for signing, and 2.0x for verification. Compared to an implementation with assembly optimized for Cortex M4, the slowdowns become more significant: 1.8x for key generation, 5.4x for signing, and 2.7x for verification (4). It’s likely that for OpenTitan, we’d end up somewhere in between. Effectively, we’d need to apply the same transformation that gets from PQClean to “This work” in the table above, but we’d be applying it to an implementation that’s closer in nature to the specialized assembly of pqm4. In terms of code size, it doesn’t seem to incur a high cost; the code size is about the same as pqm4. It’s somewhat larger than PQClean, but this is partly because PQClean separates the different Dilithium parameter sets and the memory-optimized version includes all of them.
So, from here we can conclude:
It’s possible to lower the memory consumption of Dilithium-3 to something that an OTBN with slightly expanded (e.g. 12kB or possibly even 8kB) of DMEM could accommodate.
We should expect small-multiple slowdowns from these memory optimizations: 1-2x for key generation, 3-5x for signing, and 2-3x for verification.
The cost in terms of code size should not be catastrophic.
Next, what do we learn from the two papers with implementations on modified versions of OpenTitan? This table from Towards ML-KEM & ML-DSA on OpenTitan summarizes the performance numbers for the different variants (including Enabling Lattice-Based Post-Quantum Cryptography on the OpenTitan Platform, which is cited as SOSK23) as well as other platforms:

The stack size requirements for this paper’s implementations are similar to PQClean’s Dilithium implementation; we must assume that we need to apply some of the transformations in the memory-optimization paper. For SOSK23, some computation has been moved out of OTBN, likely to save memory, and the implementation works with 32kB of OTBN DMEM. Because memory optimizations could remove some overhead and perhaps some have already been applied, it would be reasonable to expect a slightly smaller multiplier from memory optimizations there.
When we compare the performance table with the hardware area evaluations, we can see a clear tradeoff emerge between area and performance:

While the “Ext++” variant is the fastest, it also uses significantly more hardware area than “Ext”. However, for just a 12% area penalty on OTBN, “Ext” is nearly as fast. In fact, 697K cycles is close to the performance we see for ECDSA-P256 signing, currently 704K cycles – although it’s important to remember here that the Dilithium implementation still needs memory optimizations and side-channel protection to be truly comparable. Still, the performance looks very promising, and the costs in terms of area and code size would be manageable. I am very optimistic about this direction of work!
Such a detailed view of the tradeoff space is especially valuable because OpenTitan is not just one chip; it’s a library of hardware designs that can be assembled into multiple different “top-levels”, like Earl Grey and Darjeeling (we have a tea theme). So it’s not hard to imagine that, in the future, some OpenTitan designs might prioritize having the fastest post-quantum cryptography they possibly can, even though it costs area, while others might be less specialized.
In any case, it’s clear from this research that:
Connecting OTBN and KMAC has a dramatic positive effect on Dilithium performance.
Modest vector instruction-set extensions also provide a lot of speedup for a relatively small cost.
We would need to increase OTBN’s data memory and likely also instruction memory to accommodate Dilithium-3; 12kB each should be enough.
Conclusion
That’s all for this long-winded series of posts! I hope that explaining a bit about our experience and thought process has been helpful or at least entertaining to people who are also thinking about implementing PQC. This is a huge, complex, and fascinating area. Many thanks to all of the brilliant, talented researchers who have helped me understand this space and contributed to the works I cited above!
Interested in learning more? Sign up for our early-access program or contact us at info@zerorisc.com.
(1) The NIST standard, FIPS 205, renames the algorithm to SLH-DSA, but we’ll refer to it as SPHINCS+ for this post. Our implementation is compatible with round-3 SPHINCS+ for last year’s chips and will be compatible with FIPS 205 for future versions.
(2) OpenTitan is a large open-source project stewarded by lowRISC on which many organizations, including zeroRISC, collaborate.
(3) It would be technically possible to run the Dilithium and Kyber reference implementations on Ibex/KMAC instead of OTBN. This would work with no hardware modifications but would be slow. As a very rough back-of-the-napkin estimate, it would take something like 89ms per Dilithium3 signature, much slower than even OTBN with more memory and no ISA changes. (The pqm4 measurement is 127ms, 31% of that is SHAKE, and I'm using the estimate from post 1 that hardware SHAKE takes 3% of the time software SHAKE does).
(4) Specifically, the implementation from Compact Dilithium Implementations onCortex-M3 and Cortex-M4 (2021).
Landing SPHINCS+ on OpenTitan
This is part 2 of 3 in an experience report about implementing SPHINCS+ (aka SLH-DSA) for secure boot in OpenTitan root of trust (RoT) chips. SPHINCS+ is a post-quantum secure signature algorithm and one of the four winners of NIST’s post-quantum cryptography competition; the final standard was recently released as FIPS 205. On this exciting occasion...
This is part 2 of 3 in an experience report about implementing SPHINCS+ (aka SLH-DSA) for secure boot in OpenTitan root of trust (RoT) chips (1, 2). SPHINCS+ is a post-quantum secure signature algorithm and one of the four winners of NIST’s post-quantum cryptography competition; the final standard was recently released as FIPS 205. On this exciting occasion, we hope that sharing our experience with SPHINCS+ will help others who are considering migrating to PQC, especially for firmware signing. Read part 1 here.
This post will focus on the implementation and organizational aspects of adopting SPHINCS+ for OpenTitan’s current-generation “Earl Grey” chips. We’ll cover:
how the idea to use SPHINCS+ for secure boot on Earl Grey came about,
the process of preparing an RFC and getting it approved within OpenTitan, and
how we adapted and optimized the reference implementation to suit Earl Grey.
This will probably be the most detailed and longest blog post in the series; I think a really cool part of working on an open-source project is that we leave a public trail of discussions we’ve had and code we’ve merged, and I want readers to be able to follow that trail. So I’ll link liberally to commits and GitHub issues throughout this post. I also want to draw attention to the non-technical infrastructure I discuss here, especially the RFC process (part of the general “Silicon Commons” approach to collaborative open-source hardware projects) and how OpenTitan development works across multiple organizations.
Idea and Prototyping
The original suggestion to try running SPHINCS+ on OpenTitan came from Peter Schwabe, one of the original authors of SPHINCS+, following a serendipitous meeting at CHES 2022. He suggested that we could probably run the reference implementation efficiently on our platform without any hardware changes. With his help, we were able to strip out the non-verification code, replace the software hash function with calls to our hardware implementation, set up a test case, and successfully verify a signature in hardware simulation the next day. (You can see the excited commit message where I wrote “WORKING!” – I remember clearly the moment when I saw “verification passed” print on my screen for the first time.) The availability of an optimized, public-domain reference implementation was crucial here; it made getting the first prototype off the ground a breeze, and allowed us to continually check our implementation against reference test vectors throughout the whole development cycle to make sure we didn’t introduce bugs.
After that first signature, we spent a few weeks optimizing the implementation and experimenting with different parameter sets. You can see the whole trail of those experiments recorded on my prototyping branch: jadephilipoom/opentitan:sphincsplus. We were able to find a 3x speedup in verification time overall with platform-specific optimizations, mostly adjusting the KMAC block driver and assuming word-aligned buffers everywhere. The reference implementation has to assume that some internal buffers might be byte-aligned, but in OpenTItan’s ROM code there was an early design decision that absolutely everything should be word-aligned, and it’s OK to assume so. In my opinion, this decision has paid off extremely well, with benefits not just for performance but also for defense against power side-channels when handling secret data. (Byte-writes are generally more vulnerable than word-writes in that context, because there are fewer possibilities for the attacker to choose between.)
The benchmarks are all documented on the prototyping branch, along with instructions to reproduce them if you’re curious. We compared all the parameter sets at first but quickly realized that we wanted to target the shake-128s-simple parameter set, so the benchmarks focused on that. Below is the summary of what we tried during the initial prototyping and the effect on performance for shake-128s-simple:

You can find (or create!) benchmarks for other parameter sets by checking out the branch and running more tests.
It’s worth noting that the final version of SPHINCS+ in ROM today is even faster; we were able to bring shake-128s-simple down to just under 13ms, mostly with more word-alignment. After recently switching to SHA2 parameters (see issue #23144 and pull request #23732) for the upcoming Earl Grey chips, the verification takes about 9.3ms.
These experiments showed that SPHINCS+ was fast enough to run as an option for secure boot. It was still about 6x slower than RSA-3072 and 3x slower than ECDSA-P256, so we wouldn’t want to force all users of the chip to run it. However, we could potentially add a field to the chip’s one-time programmable (OTP) memory configuration to let us choose to enable post-quantum secure boot for certain chips at manufacturing time, an option that was suddenly looking feasible much earlier than expected.
Around the time we concluded the optimization experiments, we started evaluating what it would take to land this code in the very first Earl Grey tapeout. The timing was ambitious. This was late November 2022, and we had already scheduled a tapeout for the first chips. Based on that schedule, we needed to lock in the ROM implementation, with no further changes, by June 2023. Seven months to put a working prototype into production use might sound like plenty of time, but not for silicon where you can’t compile your way out of a problem. There is a lot of work in between passing an initial test and having code that is ready to go into ROM. For example, we needed to decide how the PQC option would interact with the existing classical signature verification, change the boot manifests to accommodate multiple signature types, add SPHINCS+ signing capability to the Rust-based opentitantool utility, adjust all the code to match OpenTitan’s specific style guide, and of course run extensive tests – not just on the signature verification core code but also on its integration with the rest of the ROM.
Before we did any of that, because this was a major change we needed to go through the RFC process and seek approval from the OpenTitan Technical Committee. Big decisions in OpenTitan can’t be made unilaterally by design. Lots of organizations collaborate to make the project possible. It’s vitally important to the health of the project that decisions are made fairly and transparently, giving everyone a chance to provide feedback, object to or adjust new proposals.
Creating an RFC
In December 2022, I presented an RFC to the OpenTitan Technical Committee, explaining the results from the initial prototype and optimization experiments and mapping out the estimated cost in terms of implementation effort, boot time, and code size.
One important decision for the RFC was whether enabling the SPHINCS+ secure boot flow should disable the classical flow. We decided if SPHINCS+ was enabled, both the classical and PQC flows would run, and the code would need two signatures. Although SPHINCS+ is based on the security of hash functions and is cryptanalytically low-risk, the flow was also completely new, and we didn’t want to risk introducing a new bug and undermining security. Plus, given that SPHINCS+ took quite a bit longer than classical verification, adding the classical verification time on top of it wasn’t much of a relative cost.
Safe Comparison
Another important detail was how to defend the sensitive final comparison against fault injection attacks. Some general principles behind defending against fault injection attacks in software, at a very high level, are:
It’s easier to glitch one bit than several at once, so avoid situations where a single bit-flip can bypass a security check (e.g. a security-critical if/else statement).
For enums, use values with a high Hamming distance from each other, making it hard for an attacker to glitch one value into another one that sends the code down a different path.
Sometimes, attackers can trick the code into reading unexpected values that exist in the logic (for example, by preventing a register from updating). Therefore, ensure any values that mean “passed security check” are not just hanging around in a register; they should be constructed slowly as the code goes through its intended path.
Like RSA and ECDSA, the signature verification procedure is structured so that it does a big computation on some combination of the public key, message, and signature, then checks the resulting value against part of the original input values (in SPHINCS+, the public key root). If the signature is valid, the two should be equal. If you’re an attacker and you want to bypass secure boot, this is the comparison you should target; by causing that single comparison to say “yes” when it should say “no”, you can cause an invalid signature to be accepted. Luckily, we had already implemented a safe comparison for the classical flow (see pull request #10024, and fellow formal methods nerds might also appreciate the small proof that shows this algorithm produces the right final result). Now, we just needed to adapt the design to work with both signatures.
The original design worked by taking advantage of the fact that we don’t want to produce a boolean true or false from the comparison. Ultimately, we need a “magic” 32-bit constant, kFlashExec, if the comparison succeeds. That high-Hamming-weight constant (and no other value) would allow us to unlock flash for the next boot stage. This makes it easier to defend the implementation from fault attacks, because we’re never relying on a single bit or branch. We generated pre-computed 32-bit shares of the magic value, meaning values x0 through xn-1 such that:

We chose the number of shares (n in the equation above) so that the total length of the shares, when concatenated, was equal to the length of the signature values we needed to compare. Then we would start with an all-zero result value. For every word of the two values we needed to compare, we would XOR (⊕) the two next words we needed to compare with the result value and also the next share of the precomputed list of shares. There was also an extra value called “diff” to make sure it was impossible to accidentally arrive at the correct value. It directly checked if the XOR of the two words was zero, and if so (or if the previous diff was nonzero), it set both the result value and the diff to all-ones.
We needed to adapt this design so it could generate kFlashExec only if either:
the classical verification passed and SPHINCS+ was disabled, or
both verifications passed and SPHINCS+ was enabled.
The approach we chose was to pick special values A and B, as well as special values for the “enable” and “disable” OTP settings, so that:

Then, instead of using shares for kFlashExec, we would have the classical signature verification routine use shares for A, and the SPHINCS+ comparison use the same strategy with shares for B. We’d XOR the results of these comparisons with the SPHINCS+ enablement field, so that either of the expected cases (but no unacceptable ones) would construct the correct value.
With this crucial detail planned out, I was ready to present the RFC to the Technical Committee. In one of the committee’s regular meetings, I presented the document and answered questions. Committee members gave feedback and requested more details in certain sections, for example on the changes to the manifest format. Per normal procedures, they didn’t vote to approve the RFC in that first meeting; rather, the RFC contributors made the changes and TC members deliberated offline. At the next meeting, they held a (successful!) vote approving the proposal.
Initial Implementation
By the time the RFC was done and approved, it was early January 2023; we had less than 6 months before the ROM freeze deadline. We quickly got to work. Starting with adjusting the reference implementation to match the code style conventions in the OpenTitan repository, we slowly merged the prototype implementation with about a dozen pull requests (see for example #17093, #17221, #17295, and #17367), each with a small, digestible chunk of code to undergo review. For now, nothing actually called the code.
As of pull request #17326 in late February, we had a complete implementation and were ready to integrate the code into the boot flow and surrounding infrastructure. We reworked how the ROM code represented keys to handle both classical and SPHINCS+ keys (see pull request #18512), and implemented the safe final comparison from the RFC (see pull request #17995). We added SPHINCS+ support for opentitantool based on the pqcrypto Rust crate (see pull requests #18184 and #18041). Finally, we added a new manifest extensions capability to the format for boot manifests, and incorporated the changes into opentitantool so we could sign images with SPHINCS+ signatures from the command line (see pull requests #18584 and #18667). The opentitantool support also allowed us to run integration tests that checked the signature verification code operated as expected with the whole boot sequence and correctly accepted or rejected the signatures from pqcrypto.
Maintenance and Updates
Since the initial implementation for the first Earl Grey tapeout, there have been a few additional updates and changes to the SPHINCS+ code for OpenTitan that will come into effect for the next tapeout. The old version was compatible with the round 3 SPHINCS+ submission to the NIST competition and used SHAKE as the hash function. The new version will be compatible with the FIPS 205 standard and use SHA-256 as the hash function.
First, NIST made a few changes for the FIPS 205 standard that are not backwards compatible. For example, there was a small endianness change in an internal routine that changed signature values completely. We implemented it in May 2024 (see pull request #22953) in preparation for the next tapeout. This was a somewhat tricky change to make, especially since NIST hadn’t released test vectors for it and the pqcrypto crate we used for opentitantool didn’t yet include it. The reference implementation had added a branch with the endianness change, so we were able to re-generate tests for part of our testing infrastructure that way. But another part of our test infrastructure directly pulled the NIST tests from round 3 of the PQC competition, so we needed to change it. Instead, as discussed in the comments on pull request #22953, we set up self-hosted test vectors generated from the right branch of the reference implementation to replace the round 3 tests.
We also needed a new way to generate signatures with opentitantool before the changes would be compatible with our integration tests and signing utilities. We discussed the issue at one of the regular Software Working Group meetings. This is a good forum for smaller-scale decisions, where OpenTitan maintainers from different organizations can informally coordinate and seek feedback on engineering decisions. There, we decided to directly link the reference implementation into opentitantool with bindgen rather than, for instance, look for a different Rust crate. This option would give us more future flexibility, including to experiment with alternative parameter sets like we’ll discuss in the next post. We integrated the reference implementation into our infrastructure and generated the bindings so that I could switch opentitantool to use them (see pull requests #23049 and #23104).
There were also two smaller code changes for the new version; domain separator support to match the FIPS 205 standard (see pull requests #23762 and #23765), and a small bugfix from the upstream reference implementation (see pull request #22894). The bug didn’t affect any of the parameter sets that had been submitted as part of the PQC competition, but was problematic when experimenting with different, alternative parameters.
Finally, we changed the parameter set from SHAKE to SHA-2, as I discussed a bit already in the last post. In May 2024, just before a code freeze, we received a time-sensitive request to switch to SHA2 parameters to maintain compatibility with project partners’ infrastructure. Luckily, we were able to take advantage of the existing organizational and technical infrastructure to evaluate the effort and risk of the change, agree on a plan, and implement and test it in time. First, we wrote an RFC for the change and the TC approved it. To help inform the decision, we did some quick performance estimates to check if there would be an impact on verification speed. In general, SHAKE is faster than SHA-2 in hardware. However, our SHAKE implementation is masked for side-channel protection and the SHA-2 implementation isn’t, so it runs a little bit faster. Also, we had implemented a new save/restore feature for the SHA-2 accelerator hardware since the first tapeout (see pull request #21307), which we could use to accelerate a performance-critical part of SPHINCS+. After the Technical Committee approved the RFC, we updated multiple parts of the test infrastructure to include SHA-2 parameter sets (see pull requests #21681 and #23598), and then implemented the extra bits of code (e.g. MGF1) that we needed and swapped over the implementation (see pull request #23710 and #23732). Then we went through and, using similar techniques as we had for SHAKE as well as the save/restore feature, optimized the code so that it would run a significant few milliseconds faster (see pull request #23761). For code size and schedule reasons, we fully swapped over the implementation and don’t support the SHAKE parameter sets as an option in this version. For future OpenTitan chips, we’re considering supporting both.
Closing Words and Thanks
And of course, like most technical projects, we build on the work of many others; in this case, we benefited greatly from the SPHINCS+ authors making a high-quality reference implementation and test vector generation script available under a permissive open-source license. We strongly believe that accessible, quality implementations are indispensable – in hardware and software alike! So thank you to the SPHINCS+ authors, especially Peter for suggesting that we try running SPHINCS+ and helping us set up the first experiments.
I think of this post as sort of a case study in how a major feature on OpenTitan chips was introduced, accepted and maintained. It takes a village to tape out a chip, and landing this feature required tons of expertise and hard work from people with different specialties (and frequently different employers!) Heartfelt thanks to all of the contributors on the OpenTitan project who wrote design docs, pushed code, reviewed PRs, and adjusted infrastructure to make this possible: Alphan, Jon, Ryan, Chris, and many more.
Stay tuned for the third and final post in this series, where we’ll focus on exciting future possibilities for PQC on OpenTitan: alternative SPHINCS+ parameter sets and lattice cryptography.
Interested in learning more? Sign up for our early access program or contact us at info@zerorisc.com.
(1) The NIST standard, FIPS 205, renames the algorithm to SLH-DSA, but we’ll refer to it as SPHINCS+ for this post. Our implementation is compatible with round-3 SPHINCS+ for last year’s chips and will be compatible with FIPS 205 for future versions.
(2) OpenTitan is a large open-source project stewarded by lowRISC on which many organizations, including zeroRISC, collaborate.
Post-Quantum Secure Boot on OpenTitan
This is part 1 of 3 in an experience report about implementing SPHINCS+ (aka SLH-DSA) for secure boot in OpenTitan root of trust (RoT) chips. SPHINCS+ is a post-quantum secure signature algorithm and one of the four winners of NIST’s post-quantum…
This is part 1 of 3 in an experience report about implementing SPHINCS+ (aka SLH-DSA) for secure boot in OpenTitan root of trust (RoT) chips (1, 2). SPHINCS+ is a post-quantum secure signature algorithm and one of the four winners of NIST’s post-quantum cryptography competition; the final standard was released yesterday as FIPS 205. On this exciting occasion, we hope that sharing our experience with SPHINCS+ will help others who are considering migrating to PQC, especially for firmware signing.
The OpenTitan project has a complete SPHINCS+ implementation in mask ROM, which means post-quantum secure boot has been supported since the very first OpenTitan “Earl Grey” chip samples came back earlier this year. In this post, we’ll cover:
why post-quantum cryptography is important,
a quick, high-level primer on SPHINCS+, and
how SPHINCS+ compares to other post-quantum algorithms in this context.
Stay tuned for future posts with more focus on the implementation and our future plans!
Why now?
First, let’s take a step back and answer the basic question of motivation: why is it important to implement post-quantum cryptography now? No quantum computer currently exists that could break “classical” signature algorithms like RSA or ECDSA. In fact, current known quantum computers are quite far off from that goal; according to the Global Risk Institute’s 2023 survey, quantum computing experts were asked to estimate the chance, by various deadlines, of a quantum computer being able to crack RSA-2048 in a day. The experts gave it a 4-11% probability of happening by 2028, and a 17-31% probability of happening by 2033. The estimates don’t break 50% until 2038. So why start defending against quantum computers now?
For secure silicon, the most crucial factors to consider are that (a) hardware development timelines are long, and (b) the first signature verification during boot is critical to the trust model. A chip we design today might well be in the field 5, 10, or even 20 years from now, and the ROM code that does the signature verification can never be changed after manufacturing. If the ROM can only verify ECDSA signatures, then a quantum attacker who can forge an ECDSA signature could run their own code in early boot. This would break fundamental features of these devices, like OpenTItan’s ownership transfer; the attacker could insert malicious code without the device owner’s knowledge. So, even if the risk is low today, we still need to be ready for an uncertain future.
One notable factor we don’t need to worry about in this context is “harvest now, decrypt later” attacks. In those attacks, a patient attacker collects encrypted communications now and then decrypts them with a quantum computer many years in the future to find out what was said. This is an important concern for many contexts in modern cryptography. However, since secure boot doesn’t involve encryption at all, it’s not a concern here.
Finally, from a big-picture perspective, it will take the world a lot of time to agree on and migrate to post-quantum cryptography. The NIST competition was first announced in 2016, and (some of) the standards are now finally out 8 years later. It took a massive amount of time and effort from cryptographers to invent and analyze dozens of algorithms, but that work was just the start. Post-quantum cryptography generally involves much larger signatures and keys and/or much slower running times than classical cryptography. Migrating real-world live systems to use these algorithms will be a many-year process requiring global coordination; we can’t afford to put it off until it becomes an emergency.
About SPHINCS+
As post-quantum algorithms go, SPHINCS+ is refreshingly familiar. It’s a hash-based algorithm, meaning that it doesn’t rely on any new cryptographic constructs like lattices – instead, the internal mathematical structures are trees of hashed values. That makes SPHINCS+ more conservative security-wise than lattice-based schemes; since we’ve been studying hash functions for a long time, it’s unlikely that a new cryptanalytic result is going to suddenly weaken the security bounds. Hashing speed is the most important performance factor in SPHINCS+ by far. In particular, there’s a chain operation that repeatedly runs the hash function and can take up to 95% of the runtime, depending on the parameter set, platform, and hashing speed. Even with our hardware-accelerated version, where hashing is much faster compared to non-hash operations, the chain operation is about 79% of the runtime.
Another interesting aspect of SPHINCS+ is that it’s a signature framework; you can adjust 6 different parameters and freely swap out the hash function to make signature algorithms with different performance and size characteristics. The authors selected 36 specific parameter sets in their submission to the NIST competition. For each of the 3 security levels they targeted, they picked two settings for the framework parameters, one that targeted small signatures, the “s” parameters, and one that targeted fast signature generation, the “f” parameters. Those 6 options could each be deployed with one of 3 different hash functions (SHA2, SHAKE, and Haraka), and one of two different algorithmic variants “simple” and “robust”. NIST dropped the Haraka option and the “robust” variants, reducing the original 36 parameter sets to 12 for FIPS 205.
So, when we say OpenTitan has SPHINCS+, we need to be a little more specific; the first round of chips supported the shake-128s parameter set, meaning that the hash function is SHAKE, the security level is equivalent to AES-128, and the remaining parameters are tuned for small signatures at the expense of signing speed (3). We chose the AES-128 security level to match our existing classical signature verification. For a lattice-based scheme, it might make sense to go a level up, but since SPHINCS+ is hash-based, our risk assessment concluded it wasn’t necessary in this case. For firmware signing, the “s” small-signature parameter sets are clearly better suited than the fast-signing “f” parameter sets; “s” has faster signature verification time as well as smaller signatures, and since signing happens infrequently, there’s no problem with waiting a bit longer to generate signatures.
The next tapeout of Earl Grey chips will support the sha2-128s parameter set; the same settings, except with SHAKE swapped out for SHA-2. OpenTitan has hardware accelerators for both operations (the KMAC block for SHAKE and other Keccak-family functions, and the HMAC block for SHA-2), so either option works well. For signing or key generation, when secret values are involved, it would definitely make more sense to use SHAKE, because the KMAC block has masking measures to protect against physical side-channel attacks and the HMAC block does not. However, since verification doesn’t handle secret values, the lack of masking measures actually becomes an advantage. SHA-2 operations run slightly faster than SHAKE on OpenTitan because they don’t include overhead from masking. We also considered that it might be easier to interoperate with code-signing infrastructure using SHA-2 than SHAKE, since SHAKE is newer and not everything yet supports it. In the future, both hash functions may be supported.
Why SPHINCS+?
In addition to SPHINCS+, NIST is standardizing two other new signature algorithms: Falcon and Dilithium. (Dilithium is already released as ML-DSA in FIPS 204; the Falcon standard is not yet published.) There’s also LMS and XMSS, stateful hash-based signatures that have been standardized for some time. So, out of all of these options, why does SPHINCS+ make sense for OpenTitan?
First, let’s address the stateful hash-based signature schemes, LMS and XMSS. On the surface, they seem to have generally better stats than SPHINCS+ 128s. The LMS parameter set (n=24, h=20, w=4), for example, has signatures about ¼ the size of 128s, and probably would verify signatures about twice as fast on OpenTitan. Furthermore,And these schemes are hash-based, so they are about as safe from new cryptanalytic breaks as SPHINCS+ is. However, there’s one big catch: the “stateful” part. LMS and XMSS maintain a set of one-time-use keys, and must remember which ones they’ve already used. If you ever sign twice without changing the state then the security guarantees immediately break down. This poses a fair amount of operational risk. For example, backing up and restoring a stateful private key must be done very carefully; a signature between the backup and the restore could mean game over. In this case, the OpenTitan project decided we’d rather deal with large signatures than accept additional complexity for the signing infrastructure, but this is ultimately a judgment call. You can find more discussion of the risks and mitigation techniques for stateful signatures in IETF RFC 8554 and the public comments for the LMS/XMSS NIST standard.
So what about Falcon and Dilithium? The bottom line is that, given the current Earl Grey hardware and OpenTitan’s security requirements, these algorithms would be somewhat slower and riskier than SPHINCS+, and the reduction in public key + signature size they would offer is not game-changing enough to justify those tradeoffs. (For the future, we are optimistic about hardware modifications that would accelerate lattice cryptography on OpenTitan, which we’ll discuss in more detail in a later post.)
Falcon and Dilithium are based on newer, lattice-based cryptography rather than hash functions. This means that there’s a higher risk of new attacks that would weaken their security bounds or potentially break them completely. It’s not a hypothetical concern; this is exactly what happened to SIKE, an isogenies-based scheme that had advanced to the final stages of the NIST competition and withstood years of analysis. Given the long timescales of hardware and the fact that the signature scheme can’t ever be updated, this is problematic. We could, however, minimize the risk by using security levels one step higher than we strictly need, meaning Falcon-1024 or Dilithium3 (aka ML-DSA-65) instead of Falcon-512 or Dilithium2. This is in line with the recommendation of the Dilithium authors themselves.
Even with these beefier parameter sets, we’d get a substantial reduction in public key + signature size compared to SPHINCS+, which is at about 8kB, versus 5kB for Dilithium3 and 3kB for Falcon-1024. Dilithium and Falcon public keys are too large to store in the chip’s OTP like we do for ECDSA and SPHINCS+, but we could get around this issue by hashing the public key, storing only the hash, and passing the full public key along with the signature. Therefore, it makes sense to look at the combined public key + signature size here to understand the amount of data we’d need to include with the signature in practice. Any of those numbers take a significant chunk of space away from the space we have for the code we’re signing, but SPHINCS+ is significantly larger than the lattice-based schemes. Thus,So signature size is definitely a favorable point in favor of Dilithium and Falcon.
Performance is a bit tricky to estimate, but we can get a rough idea from the pqm4 project’s benchmarks for ARM Cortex M4. Thanks to the pqm4 authors for making these incredibly easy to access and interpret! OpenTitan’s Ibex core is vaguely similar to the Cortex M4 in that it’s a memory-constrained 32-bit processor. However, there are some major differences: for example, Ibex doesn’t have floating-point instructions. This is more important for Falcon than Dilithium, so our estimates are more certain for the latter. With that disclaimer, the most relevant benchmarks are reproduced here, alongside OpenTitan’s SPHINCS+ measurements:

Let’s break this down a bit. The “cycles” column records the CPU time needed for signature verification. The “hash %” column is the amount of time spent on hashing; in the case of both Dilithium and Falcon, the hashing is SHAKE. This column gives us some insight into how much we can speed up the implementation on OpenTitan by using the SHAKE accelerator, compared to a platform without hash acceleration. So, even though the Dilithium runtimes are slower, we have a bit more leeway to speed them up than we do for Falcon. With SPHINCS+, since the vast majority of runtime is hashing, we can get really dramatic speedups.
The last two columns are important factors for Earl Grey’s memory-constrained environment. The “memory” column records how much stack space the implementation needs, and the “code size” column records the amount of space needed to store the code itself. Unfortunately, pqm4’s benchmarks don’t include a code size metric for the verify routine on its own. Still, we can get a rough idea of where the dragons lie. For example, since our ROM is only 32kB, we can make an educated guess that the Falcon implementations might be difficult for us to fit. These memory metrics are definitely a point in the column for SPHINCS+.
We can – again, very roughly – estimate the speedup more precisely with some back-of-the-envelope linear equations. If we make the approximation that the non-hash components of the implementation will perform similarly, we can use the known values for SPHINCS+ to solve for the difference in hash performance.

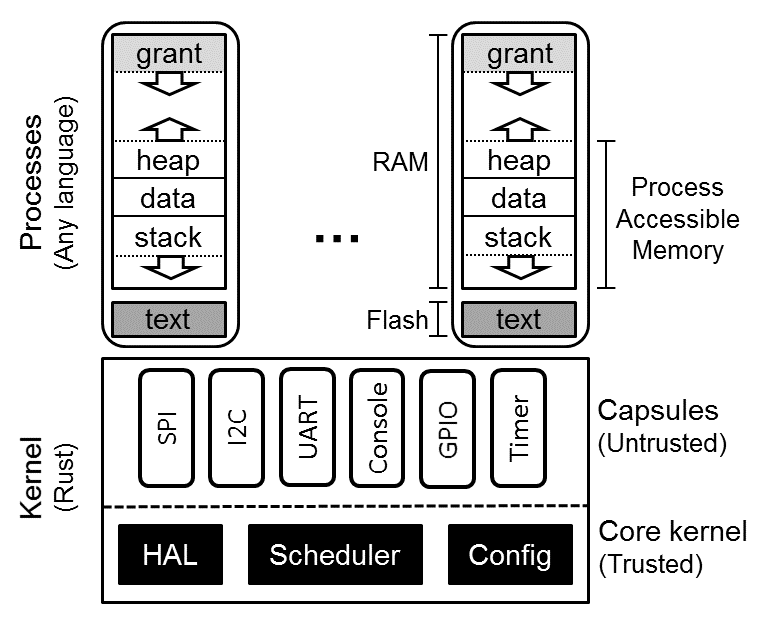{kind=link}
In the above equations, t is the total number of cycles for OpenTitan’s Earl Grey and the Cortex M4 respectively, n is the time spent on non-hashing operations, h is the number of hashing operations, and s is the average time taken for a hashing operation. If we know the total cycles on both platforms, and we know the ratio of time that’s spent on hashing for Cortex M4 (which lets us solve for n), we can derive the value of (sot / sm4), a measurement of how long the average Earl Grey hashing operation takes compared to the Cortex M4 version. Applying these estimates to the known SPHINCS+ shake-128s numbers tells us that the hardware-accelerated SHAKE takes on average 3% of the time that the software SHAKE does, and gives us a ballpark estimate of around 1.5 million cycles for “clean” Dilithium3 and 3.4 million cycles for the “m4stack” variant. Falcon-1024 comes out to 1.2 million cycles for “clean” and 600K cycles for “m4-ct”.
Because the estimate makes some sweeping assumptions about the similarity of “Earl Grey” and Cortex M4, and the hashing operations for the different schemes, we shouldn’t interpret this as anything more precise than a ballpark estimate. Still, the rough numbers don’t give us reason to believe that Falcon or Dilithium verification would run much faster than SPHINCS+ on our current hardware, and they might even run slower, especially when we consider that code size might disqualify “m4-ct” Falcon. This makes sense, simply because Earl Grey is currently better at accelerating hash-based computations than lattice-based ones. For example, there are currently no vector instructions on Earl Grey, which are very handy for lattice cryptography.
So, in summary, we expect that on current Earl Grey hardware:
speed comes out slightly in favor of SPHINCS+
signature size is better with Dilithium and Falcon
code size + stack usage is lower with SPHINCS+
cryptanalytic risk is lower with SPHINCS+
Since the SPHINCS+ signature size of 8kB is in the high-but-manageable range for today’s Earl Grey chips, SPHINCS+ is more suited to this use-case. This doesn’t mean we’re not excited about lattice cryptography – quite the opposite! But for now, for this purpose, SPHINCS+ just makes the most sense.
That’s all for part 1! In part 2, we’ll focus more on implementation and organizational details: how the code actually landed in time for tapeout and how OpenTitan’s RFC process works for big changes like this. Then in part 3, we’ll focus on the future: how the tradeoff space discussed in this post may change with better lattice cryptography support and new SPHINCS+ parameter sets.
(1) The NIST standard, FIPS 205, renames the algorithm to SLH-DSA, but we’ll refer to it as SPHINCS+ for this post. Our implementation is compatible with round-3 SPHINCS+ for last year’s chips and will be compatible with FIPS 205 for future versions.
(2) OpenTitan is a large open-source project stewarded by lowRISC on which many organizations, including zeroRISC, collaborate.
(3) This is also called “L1” in the context of the NIST competition. The reason to say roundabout things like “equivalent to AES-128” or “L1” instead of “128 bits of security” is because of Grover’s algorithm, which theoretically halves security bound for quantum computers brute-forcing large numbers. However, it’s questionable whether Grover weakens the security bound significantly in practice, so saying “equivalent to AES-128” lets us all put it aside and allow a specific exception for quantum brute-force.
Introducing the zeroRISC Technical Blog
Stay tuned for future posts about the exciting contributions we’ve been making to OpenTitan, other open-source projects, and the widespread security community.
Stay tuned for future posts about the exciting contributions we’ve been making to OpenTitan, other open-source projects, and the widespread security community.